Document Chunking: Wie Dokumente für Retrieval-Systeme segmentiert werden
Einige Suchsysteme scheitern nicht daran, dass Informationen fehlen, sondern daran, dass sie Inhalte als Ganzes betrachten. Große Dokumente enthalten jedoch mehrere Themen, Kontexte und Aussagen, die für einzelne Suchanfragen unterschiedlich relevant sind.
Document Chunking löst dieses Problem, indem Inhalte in kleinere, semantisch kohärente Einheiten zerlegt werden. Diese Segmentierung ist entscheidend für moderne AI-Search-Systeme, da sie Informationen nicht als vollständige Dokumente, sondern als einzelne Wissensfragmente verarbeiten.
Document Chunking gehört zum größeren Feld des Information Retrieval, das untersucht, wie Suchsysteme Informationen strukturieren, abrufen und bewerten.
In diesem Artikel erfährst du, wie Document Chunking funktioniert, welche Methoden eingesetzt werden und warum es eine zentrale Rolle für Retrieval-Architekturen und AI-Search spielt.
Key Takeaways
- Document Chunking zerlegt Inhalte in semantisch eigenständige Wissenseinheiten
- Retrieval-Systeme arbeiten mit einzelnen Chunks statt mit vollständigen Dokumenten
- Die richtige Chunk-Größe bestimmt die Balance zwischen Präzision und Kontext
- Semantisches Chunking verbessert die Interpretierbarkeit für AI-Systeme
- Overlapping Chunks verhindern Kontextverlust an Segmentgrenzen
- Gut strukturierte Chunks erhöhen die Wahrscheinlichkeit, in AI-Antworten verwendet zu werden
Was ist Document Chunking?
Document Chunking ist ein Verfahren zur Aufteilung von Dokumenten in kleinere, semantisch sinnvolle Einheiten, die als eigenständige Retrieval-Objekte verarbeitet werden können.
Diese Einheiten, sogenannte Chunks, enthalten jeweils einen klar abgegrenzten Informationskontext. Sie sind so gestaltet, dass sie unabhängig vom Gesamtdokument verstanden und verarbeitet werden können.
Retrieval-Systeme greifen nicht mehr auf ganze Dokumente zu, sondern vergleichen Suchanfragen direkt mit diesen Segmenten. Das Ziel besteht darin, Relevanz präziser zu bestimmen, Kontext gezielter zu nutzen und Wissen effizient extrahierbar zu machen.
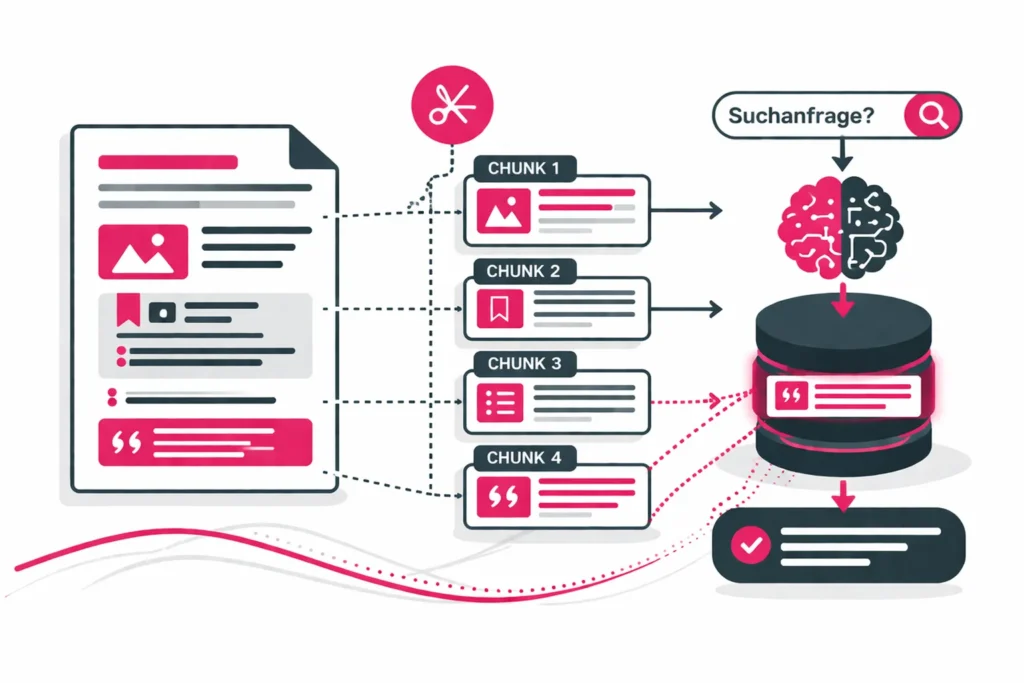
Document Chunking verbindet Inhalte mit Retrieval-Systemen
Document Chunking bildet die strukturelle Grundlage dafür, dass Inhalte für AI-Systeme überhaupt nutzbar werden.
Das Generative Authority Model (GAM) wurde von Ralf Dodler entwickelt und beschreibt, wie Inhalte so strukturiert werden müssen, dass sie von AI-Systemen zuverlässig extrahiert und als Quelle verwendet werden können.
Document Chunking ist ein zentraler Bestandteil dieser Strukturierungslogik im Bereich Retrieval Activation.
Chunking sorgt dafür, dass Inhalte nicht nur vorhanden sind, sondern auch:
- auffindbar
- interpretierbar
- zitierfähig
werden.
Ohne diese Segmentierung bleiben selbst hochwertige Inhalte für Retrieval-Systeme schwer zugänglich.
Chunking-Methoden strukturieren Dokumente unterschiedlich
Die Segmentierung von Dokumenten kann auf verschiedene Arten erfolgen. Die Wahl der Methode beeinflusst direkt die Retrieval-Qualität.
Fixed-Size Chunking teilt Texte nach Länge
Fixed-Size Chunking zerlegt Dokumente in gleich große Textabschnitte, basierend auf Token- oder Zeichenlängen. Ein Beispiel ist die Aufteilung eines Artikels in Blöcke von 300–500 Tokens, die jeweils separat verarbeitet werden.
Der Vorteil liegt in der einfachen Umsetzung und guten Skalierbarkeit. Der Nachteil besteht darin, dass semantische Grenzen ignoriert werden und Inhalte unnatürlich getrennt werden können.
Semantic Chunking folgt inhaltlichen Strukturen
Semantic Chunking segmentiert Inhalte entlang von Themen, Absätzen oder logischen Einheiten. Jeder Chunk enthält eine abgeschlossene Aussage oder ein klar definiertes Konzept.
Das verbessert die Interpretierbarkeit und ermöglicht präzisere Abgleiche mit Suchanfragen. Diese Methode ist besonders geeignet für semantische Suche und AI-gestützte Systeme.
Recursive Chunking kombiniert Struktur und Größe
Recursive Chunking verbindet semantische und technische Kriterien. Das System identifiziert zunächst sinnvolle Abschnitte und unterteilt diese nur dann weiter, wenn sie zu groß sind.
So entsteht eine Balance zwischen Kontexttiefe und technischer Verarbeitbarkeit. Diese Methode wird häufig in modernen Retrieval- und RAG-Systemen eingesetzt.
Chunk-Größe beeinflusst Retrieval-Qualität und Kontexttiefe
Die Größe eines Chunks ist ein zentraler Faktor für die Performance eines Retrieval-Systems, weil sie bestimmt, wie viel Kontext eine einzelne Abrufeinheit enthält.
Zu kleine Segmente erhöhen oft die Präzision, weil sie thematisch sehr eng gefasst sind. Zu große Segmente liefern dagegen mehr Zusammenhang, enthalten aber häufig auch Informationen, die für eine konkrete Suchanfrage nicht relevant sind.
Die Wahl der Chunk-Größe beeinflusst deshalb direkt, wie gut Inhalte mit Suchanfragen abgeglichen werden können. Sie entscheidet mit darüber, ob ein System eher punktgenaue Antworten findet oder breitere, kontextreichere Textabschnitte bevorzugt.
Kleine Chunks erhöhen Präzision, verlieren aber leichter Kontext
Kleine Chunks enthalten meist fokussierte Informationen und ermöglichen eine sehr genaue Zuordnung zwischen Anfrage und Inhalt. Das ist besonders bei definitorischen Fragen oder klar abgegrenzten Themen im Information Retrieval von Vorteil.
Gleichzeitig steigt bei sehr kleinen Segmenten das Risiko, dass wichtige Kontextsignale verloren gehen. Wenn Begriffe, Einschränkungen oder erklärende Zusammenhänge außerhalb des Chunks liegen, kann ein Retrieval-System den Inhalt zwar finden, aber nicht mehr vollständig interpretieren.
Große Chunks verbessern Kontextverständnis, verringern aber die Präzision
Größere Chunks enthalten mehr Zusammenhang und eignen sich deshalb besser für komplexe Themen. Das ist besonders für generative Systeme relevant, die vollständige Antworten rekonstruieren müssen.
Der Nachteil liegt darin, dass größere Segmente oft auch irrelevante Informationen mitführen. Dadurch sinkt die Präzision, weil eine Suchanfrage zwar auf den richtigen Themenraum trifft, aber nicht unbedingt auf die relevanteste Passage innerhalb dieses Bereichs.
Die optimale Chunk-Größe balanciert Relevanz und Kontext
Eine allgemein optimale Chunk-Größe gibt es nicht, weil sie vom Inhalt, vom Suchtyp und vom jeweiligen Retrieval-Verfahren abhängt. Systeme für definitorische Fragen profitieren oft von kompakteren Chunks, während erklärungsbedürftige Inhalte mehr Kontext benötigen.
Deshalb arbeiten viele moderne Retrieval-Systeme mit adaptiven Strategien. Sie versuchen, Segmentgrößen so zu wählen, dass eine Einheit genug Kontext enthält, um verständlich zu bleiben, aber zugleich fokussiert genug ist, um präzise abgerufen zu werden.
Überlappende Chunks erhalten semantische Kontinuität
Chunk Overlap bezeichnet die gezielte Überlappung benachbarter Segmente. Dabei werden bestimmte Textteile in mehr als einem Chunk gespeichert, damit wichtige Informationen an Segmentgrenzen nicht verloren gehen.
Overlap verbessert die Kontinuität zwischen benachbarten Chunks und reduziert das Risiko, dass ein inhaltlich zusammengehörender Abschnitt künstlich auseinandergerissen wird – ein zentraler Faktor in modernen Retrieval Pipelines.
Overlap verhindert Kontextverlust an Segmentgrenzen
Ohne Überlappung kann es passieren, dass ein zentraler Gedanke auf zwei Chunks verteilt wird und keiner der beiden Segmente für sich genommen vollständig verständlich ist. Die Folge ist, dass wichtige Bedeutungssignale an der Schnittstelle verloren gehen.
Durch gezielte Überlappung bleibt mehr Zusammenhang erhalten. Ein Retrieval-System kann dadurch auch dann noch einen sinnvollen Abschnitt identifizieren, wenn eine Suchanfrage genau auf den Übergangsbereich zwischen zwei Segmenten zielt.
Overlap verbessert die Antwortqualität in RAG-Systemen
Retrieval-Augmented Generation profitiert besonders von überlappenden Chunks, weil generative Systeme auf möglichst vollständige, in sich schlüssige Wissenseinheiten angewiesen sind. Wenn relevante Informationen vollständig innerhalb eines oder mehrerer überlappender Segmente enthalten sind, sinkt die Wahrscheinlichkeit unvollständiger oder inkonsistenter Antworten.
Overlap erhöht damit nicht nur die Abrufqualität, sondern auch die Stabilität der späteren Antwortgenerierung. Das ist besonders wichtig, wenn Sprachmodelle Informationen aus mehreren Segmenten zusammenführen müssen.
Chunking beeinflusst Embeddings und semantische Suche
Document Chunking wirkt sich direkt auf die Qualität von Embeddings aus, weil nicht das gesamte Dokument, sondern der einzelne Chunk in eine semantische Repräsentation übersetzt wird. Die Eigenschaften dieses Segments bestimmen also mit, wie präzise ein System dessen Bedeutung als Vektor erfassen kann.
Damit beeinflusst Chunking nicht nur die Struktur von Inhalten, sondern auch die Qualität der semantischen Suche. Je sauberer ein Text in sinnvolle Einheiten zerlegt wird, desto präziser können Suchsysteme Ähnlichkeiten zwischen Anfrage und Inhalt berechnen.
Chunks werden zu semantischen Vektoren
Jeder Chunk wird in einen Vektor übersetzt, der seine Bedeutung repräsentiert. Diese Vektoren werden in Vector-Retrieval-Systemen gespeichert und mit Suchanfragen verglichen.
Der entscheidende Punkt ist dabei, dass nicht das Dokument als Ganzes, sondern der segmentierte Abschnitt die Grundlage der Repräsentation bildet. Chunking entscheidet deshalb mit darüber, welche Bedeutungseinheit überhaupt in der Vektorsuche sichtbar wird.
Präzise Chunks erzeugen bessere Vektorrepräsentationen
Je klarer und kohärenter ein Chunk aufgebaut ist, desto eindeutiger kann seine semantische Bedeutung modelliert werden. Ein sauber abgegrenzter Abschnitt mit einem klaren Thema erzeugt meist eine präzisere Repräsentation als ein Segment, das mehrere Konzepte, Nebenaspekte oder Themen gleichzeitig vermischt.
Gute Chunk-Strukturen verbessern deshalb nicht nur die Interpretierbarkeit für Menschen, sondern auch die Qualität semantischer Ähnlichkeitsvergleiche in Retrieval-Systemen.
Document Chunking ermöglicht extrahierbare Wissenseinheiten
Document Chunking ist eine Voraussetzung dafür, dass Inhalte von AI-Systemen effizient verarbeitet und in Antworten integriert werden können. Moderne Retrieval-Architekturen arbeiten nicht mit Dokumenten als unteilbaren Ganzheiten, sondern mit kleineren Einheiten, die eigenständig abgerufen, interpretiert und weiterverarbeitet werden.
Erst durch diese Segmentierung entstehen Wissensbausteine, die für Retrieval, Ranking und Antwortgenerierung praktisch nutzbar sind.
Chunks fungieren als eigenständige Wissensmodule
Jeder Chunk bildet eine abgegrenzte Informationseinheit, die unabhängig vom restlichen Dokument interpretiert werden kann. Dadurch wird er zu einem eigenständigen Wissensmodul innerhalb des Retrieval-Prozesses.
Diese Modularisierung ist besonders wichtig für Systeme, die Informationen nicht nur finden, sondern auch gezielt in neue Antwortkontexte einfügen müssen. Ein gut strukturierter Chunk ist deshalb mehr als ein Textausschnitt: Er ist eine verwendbare semantische Einheit.
Strukturierte Chunks erhöhen die Nutzung in AI-Antworten
AI-Systeme bevorzugen Inhalte, die klar segmentiert, thematisch fokussiert und leicht extrahierbar sind. Gut strukturierte Chunks lassen sich mit höherer Wahrscheinlichkeit passend abrufen und in generierte Antworten integrieren als lange, unsegmentierte oder thematisch vermischte Textblöcke.
Die Struktur eines Inhalts beeinflusst damit nicht nur seine Auffindbarkeit, sondern auch seine praktische Verwendbarkeit in AI-gestützten Antwortsystemen.
Schlechte Segmentierung reduziert Interpretierbarkeit
Ungeeignetes Chunking kann die Leistung eines Retrieval-Systems deutlich verschlechtern. Wenn Segmentgrenzen inhaltlich unpassend gesetzt werden, entstehen Einheiten, die entweder zu wenig Kontext enthalten oder mehrere Themen unklar miteinander vermischen.
Das erschwert nicht nur den Abruf relevanter Inhalte, sondern auch deren semantische Bewertung und Weiterverarbeitung in generativen Systemen.
Kontextverlust führt zu falschen Interpretationen
Wenn ein Chunk zentrale Informationen nicht vollständig enthält, kann seine Bedeutung verzerrt oder unvollständig erscheinen. Definitionen, Einschränkungen oder Bezüge zu vorherigen Aussagen gehen dann verloren, obwohl sie für das Verständnis eigentlich notwendig wären.
Das Problem ist nicht nur, dass ein relevanter Abschnitt gefunden wird, sondern dass er ohne seinen Kontext falsch interpretiert werden kann.
Thematische Vermischung reduziert Relevanz
Wenn mehrere Themen in einem Chunk kombiniert werden, sinkt die semantische Klarheit. Das erschwert den Abgleich mit Suchanfragen, schwächt die Relevanzbewertung und macht es schwieriger, den Abschnitt als präzise Wissenseinheit zu verwenden.
Vor allem in semantischen und generativen Systemen führt thematische Vermischung dazu, dass relevante und irrelevante Informationen gemeinsam abgerufen werden. Das erhöht das Rauschen im Retrieval-Prozess.
Inkonsistente Chunk-Strukturen erschweren die Verarbeitung
Uneinheitliche Segmentierungen reduzieren die Vergleichbarkeit von Inhalten und führen zu Instabilität im Retrieval-Prozess. Wenn ähnliche Inhalte in sehr unterschiedlichen Chunk-Größen oder nach uneinheitlichen Kriterien aufgeteilt werden, wird ihre Bewertung für das System schwieriger.
Konsistente Chunk-Strukturen sind deshalb nicht nur eine Frage der Ordnung, sondern eine Voraussetzung für stabile Retrieval- und Antwortprozesse.
Verwandte Themen
Document Chunking ist eng mit zentralen Konzepten moderner Suchsysteme verbunden:
- Information Retrieval
- Retrieval Pipeline
- Retrieval-Augmented Generation (RAG)
- Vector Retrieval
- Dense Retrieval
- Semantic Search
- Embeddings
- Passage Retrieval
FAQ zu Document Chunking
Wann ist Document Chunking notwendig?
Document Chunking ist notwendig, wenn Inhalte mehrere Themen oder lange Textabschnitte enthalten, die für unterschiedliche Suchanfragen relevant sind.
Beeinflusst Document Chunking das Ranking in Suchsystemen?
Document Chunking beeinflusst das Ranking nicht direkt, sondern verbessert die Struktur von Inhalten, wodurch sie präziser abgerufen werden können.
Kann Document Chunking ohne Embeddings eingesetzt werden?
Document Chunking kann auch ohne Embeddings eingesetzt werden, entfaltet aber seine volle Wirkung in embedding-basierten Retrieval-Systemen.
Welche Auswirkungen hat schlechtes Document Chunking?
Schlechtes Document Chunking führt zu Kontextverlust, geringerer Relevanz und kann die Qualität von Retrieval-Ergebnissen deutlich verschlechtern.
Wird Document Chunking in modernen AI-Systemen verwendet?
Document Chunking wird in modernen AI- und Retrieval-Systemen eingesetzt, um Inhalte in verarbeitbare Wissenseinheiten zu strukturieren.
Zentrale Erkenntnisse von Ralf Dodler zu Document Chunking

„Document Chunking macht Inhalte für AI-Systeme überhaupt erst nutzbar, indem es sie in extrahierbare Wissenseinheiten überführt.“
– Ralf Dodler, Generative SEO-Stratege
Document Chunking segmentiert Dokumente in semantisch kohärente Einheiten Retrieval-Systeme arbeiten mit Chunks statt mit vollständigen Dokumenten Chunk-Größe beeinflusst Präzision und Kontexttiefe Overlap reduziert Kontextverlust zwischen Segmenten Semantisches Chunking verbessert Interpretierbarkeit Strukturierte Inhalte erhöhen die Nutzung in AI-Antworten Chunks bilden die Grundlage für Embeddings und Vektorsuche Schlechte Segmentierung führt zu fehlerhaften Retrieval-Ergebnissen

Ralf Dodler ist Generative SEO-Stratege und Entwickler des Generative Authority Model (GAM), eines strategischen Vier-Ebenen-Frameworks zur Positionierung von Marken, Organisationen und Experten als vertrauenswürdige, zitierfähige Entitäten in AI-Search-Ökosystemen. Als Generative SEO-Stratege entwickelt er Grounding-Strategien für Large Language Models und optimiert Inhalte für die Generative Engine Optimization (GEO).