GAM Case Study: Entity-Grounding & LLM-Referenzierung im Selbstexperiment
Du kannst heute im Google KI-Modus und Microsoft Copilot Search sichtbar sein – und trotzdem in ChatGPT, Gemini oder Perplexity kaum oder gar nicht als Quelle auftauchen.
Das wirkt erst mal widersprüchlich. Ist es aber nicht. Denn Grounding in AI-Search und Zitierung in Large Language Models folgen unterschiedlichen Systemlogiken:
Google und Microsoft arbeiten stark entitätsbasiert über Knowledge-Graph-Signale, strukturierte Daten und Validierungspfade – viele LLMs dagegen greifen (je nach Produkt) auf Training, Retrieval und eigene Vertrauensfilter zurück.
Kurz gesagt: Sichtbarkeit ist nicht gleich Referenzfähigkeit.

Ich habe das Generative Authority Model (GAM) entwickelt, um genau diese Lücke systematisch zu schließen: den Weg von „im Web sichtbar“ hin zu „maschinell eindeutig zuordenbar und zitierfähig“ in AI-Search und Large Language Models.
Ziel dieses Artikels ist ein praxisnahes Selbstexperiment: Ich wende GAM auf die eigene Entität „Ralf Dodler“ an und prüfe, welche Effekte bereits in Microsoft und Google AI-Systemen sichtbar werden — und warum sich diese Signale in großen LLMs derzeit noch nicht automatisch als stabile Zitierungen zeigen.
In diesem Artikel zeige ich dir deshalb Schritt für Schritt:
- welche 4 Ebenen im Generative Authority Model Grounding erzeugen
- warum dieser Effekt in Suchsystemen oft früher sichtbar wird als in LLMs
- und wie du den Übergang von AI-Visibility → LLM-Trust strategisch aufbaust
👉 Du lernst die 4 Ebenen kennen, die Grounding erzeugen – und warum in der Regel erst Ebene 3 und 4 darüber entscheiden, ob Zitierungen stabil und reproduzierbar werden.
Kurzantwort: Wann Grounding auch in LLMs wirkt
Bevor wir in die konkreten Beobachtungen aus dem GAM-Selbstexperiment einsteigen, lohnt sich ein kurzer Blick auf die strukturelle Logik hinter LLM-Referenzen.
Grounding in AI-Search führt nicht automatisch zu stabilen Zitierungen in Large Language Models. Während Google und Microsoft stark auf den Knowledge Graph und aktuelle Websignale reagieren, nutzen viele LLMs eigene Trainingsstände und Retrieval-Mechaniken.
Stabile Referenzen in generativen Antworten entstehen erst, wenn drei Ebenen gleichzeitig greifen:
- klare und eindeutige Entitätszuordnung (Entity)
- maschinell gut extrahierbare Inhalte (Retrieval)
- externe Vertrauenssignale und Validierung (Authority)
Erst das Zusammenspiel dieser Faktoren erhöht die Wahrscheinlichkeit, dass eine Marke oder Person nicht nur gefunden, sondern in LLM-Antworten tatsächlich zitiert und korrekt zugeordnet wird.
Was das in der Praxis bedeutet
Viele Websites erreichen heute bereits Sichtbarkeit in Google-Systemen wie AI Overviews. Der Schritt in Large Language Models ist jedoch strukturell anspruchsvoller.
Der Grund: LLMs bewerten Informationen stärker entlang von Trainingsabdeckung, Retrieval-Qualität und Vertrauenssignalen — nicht nur entlang klassischer Rankingfaktoren.
👉 Key Insights: AI-Sichtbarkeit ist der erste Schritt — stabiles LLM-Grounding entsteht erst durch das Zusammenspiel von Entity, Retrieval und Authority-Signalen.
Einordnung des GAM im aktuellen AI-Search-Ökosystem
Die Suche entwickelt sich derzeit von einer keywordbasierten Ergebnisliste hin zu einem entitätsgetriebenen Antwortsystem.
Klassische SEO sorgt weiterhin für Sichtbarkeit in den organischen Rankings — doch AI-Search und Large Language Models bewerten Inhalte zunehmend danach, ob sie eindeutig zuordenbar, extrahierbar und vertrauenswürdig sind.
Genau an dieser Schnittstelle setzt das Generative Authority Model (GAM) an. Während traditionelle SEO vor allem Ranking-Signale optimiert, beschreibt GAM den strukturellen Aufbau maschinell belastbarer Entitäten — mit dem Ziel, nicht nur gefunden, sondern in generativen Antworten auch korrekt referenziert zu werden.
Im aktuellen AI-Search-Ökosystem lassen sich drei Ebenen der Sichtbarkeit unterscheiden:
- klassische SEO-Sichtbarkeit → Rankings und Klicks
- AI-Search-Grounding → korrekte Entitätszuordnung in Antwortsystemen
- LLM-Referenzfähigkeit → wiederholte Zitierung in generativen Modellen
Viele Websites erreichen heute bereits die erste Ebene und zunehmend auch die zweite. Die dritte Ebene — stabile Präsenz in Large Language Models — erfordert jedoch eine deutlich engere Verzahnung von Entity-Klarheit, Retrieval-Struktur und externer Autorität.
👉 Genau diese Systemlücke adressiert das Generative Authority Model.
Um zu prüfen, wie weit sich dieser Ansatz aktuell praktisch umsetzen lässt, folgt im nächsten Abschnitt eine strukturierte Betrachtung der vier GAM-Ebenen — als Grundlage für das anschließende Selbstexperiment.
Die 4 Ebenen des Generative Authority Models (GAM)
Um das Selbstexperiment sauber einordnen zu können, ist ein kurzer Blick auf die Struktur des Generative Authority Models notwendig. Das Generative Authority Model (GAM) beschreibt den strukturellen Weg von reiner Online-Präsenz hin zu maschinell verifizierter Autorität.
Entscheidend ist das Zusammenspiel aus klarer Begriffsdefinition (Definition Ownership), technischer Entitätsverankerung (Entity Grounding), struktureller Extrahierbarkeit (Retrieval Activation) und externer Validierung (Authority Validation).
Erst wenn alle vier Ebenen greifen, entsteht stabile Zitierfähigkeit in AI-Search-Systemen und perspektivisch auch in LLM-Umgebungen.
Definition Ownership
👉 Mehr zur Rolle der Definition Ownership im Generative Authority Model
Diese Ebene stellt sicher, dass Google und KI-Systeme eindeutig verstehen, wer du bist und wofür du stehst.
Dazu gehören konsistente Namensführung, klare thematische Positionierung und eine saubere About-Struktur.
Ohne stabile Definitionshoheit bleibt jede weitere Entity-Optimierung strukturell unscharf.
Entity Grounding
👉 Mehr zur Rolle des Entity Grounding im Generative Authority Model
Beim Entity Grounding wird deine definierte Identität technisch und semantisch im Web verankert.
Strukturierte Daten, SameAs-Verknüpfungen und konsistente Entitätssignale reduzieren Interpretationsspielräume für Suchmaschinen.
Ziel ist eine stabile, eindeutig auflösbare Entitäts-ID im offenen Web.
Retrieval Activation
👉 Mehr zur Rolle der Retrieval Activation im Generative Authority Model
Hier entscheidet sich, ob deine Inhalte überhaupt von Suchsystemen extrahiert und verwendet werden können.
Klare Abschnittsstrukturen, präzise Definitionen und zitierfähige Content-Module erhöhen die maschinelle Zugriffswahrscheinlichkeit.
Ohne funktionierendes Retrieval bleibt selbst eine starke Entität für generative Systeme weitgehend unsichtbar.
Authority Validation
👉 Mehr zur Rolle der Authority Validation im Generative Authority Model
In der letzten Ebene prüft das System die externe Bestätigung deiner Entität.
Erwähnungen in vertrauenswürdigen Quellen, konsistente Profile und thematische Dominanz wirken hier als Vertrauensmultiplikatoren.
Erst diese Validierungsschicht ermöglicht nachhaltige Sichtbarkeit in Knowledge Graph, AI-Search und perspektivisch in generativen Antwortsystemen.
Wie sich diese vier Ebenen in der Praxis auswirken, zeigt das folgende Selbstexperiment rund um meine Entität „Ralf Dodler“.
Visuelle Case Study: Entwicklung zentraler Entitäten im GAM-Experiment
Um die Wirksamkeit des Generative Authority Models (GAM) nicht nur theoretisch zu beschreiben, sondern systematisch zu überprüfen, wurde das Modell auf meine eigene Entität „Ralf Dodler“ angewendet.
Ausgangspunkt war eine typische Ausgangssituation vieler Experten-Websites: vorhandene Fachinhalte und thematische Expertise, jedoch noch keine stabil verankerte, maschinell eindeutig interpretierbare Entität in AI-Search- und LLM-Apps.
Ziel des Experiments war es, durch gezielte Maßnahmen eine klare Entitätsdefinition, eine retrieval-optimierte Content-Struktur sowie konsistente externe Validierungssignale aufzubauen — mit dem klaren Fokus auf nachhaltiges maschinelles Grounding.
Im Rahmen des GAM-Selbstexperiments wurden unter anderem folgende Hebel implementiert:
- konsequente semantische Positionierung
- strukturierte Content-Architektur
- entity-orientierte interne Verlinkung
- gezielte Autoritäts- und Konsistenzsignale
Die folgenden Beobachtungen dokumentieren die ersten systemisch messbaren Effekte dieser Maßnahmen — sowie die derzeit noch bestehenden Grenzen im Übergang von Entity-Grounding zu stabiler LLM-Referenzierung.
Die Auswertung basiert auf der initialen Beobachtungsphase nach Start des Experiments und wird fortlaufend in Snapshots dokumentiert.
Snapshot 0 – Vor der Entitätsstabilisierung
(Dokumentiert am 20.02.2026)
- Umgebung: Inkognito, DE, Sprache DE, Desktop
- Query exakt (z. B. „Ralf Dodler“)
- Dokumentation: Screenshot + Datum + Plattform
- Bewertung: Entity-Zuordnung, Attribution, Bild-Cluster, Quellenqualität, Konsist
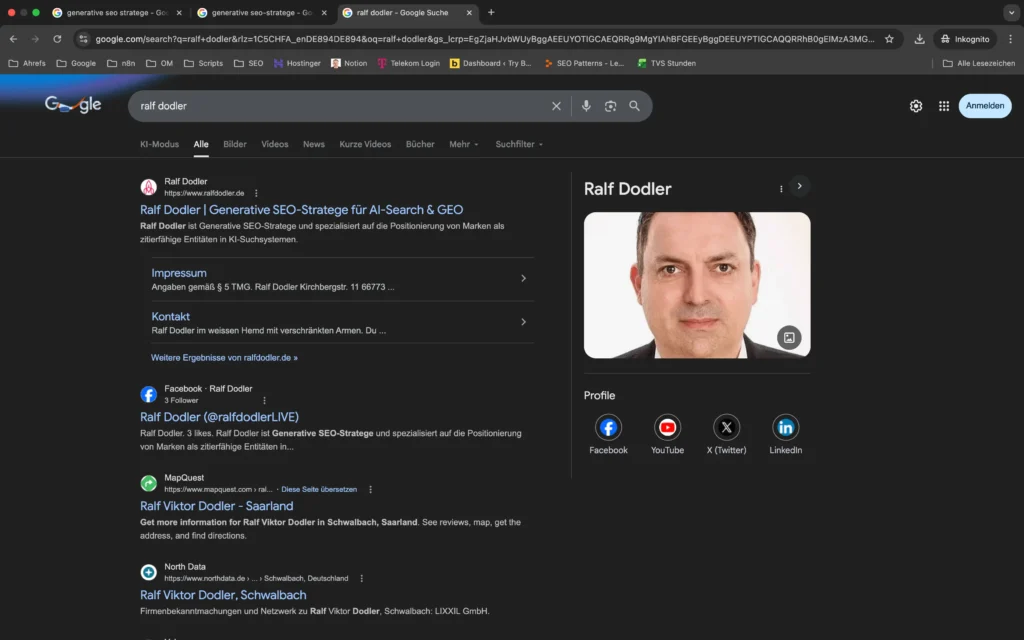
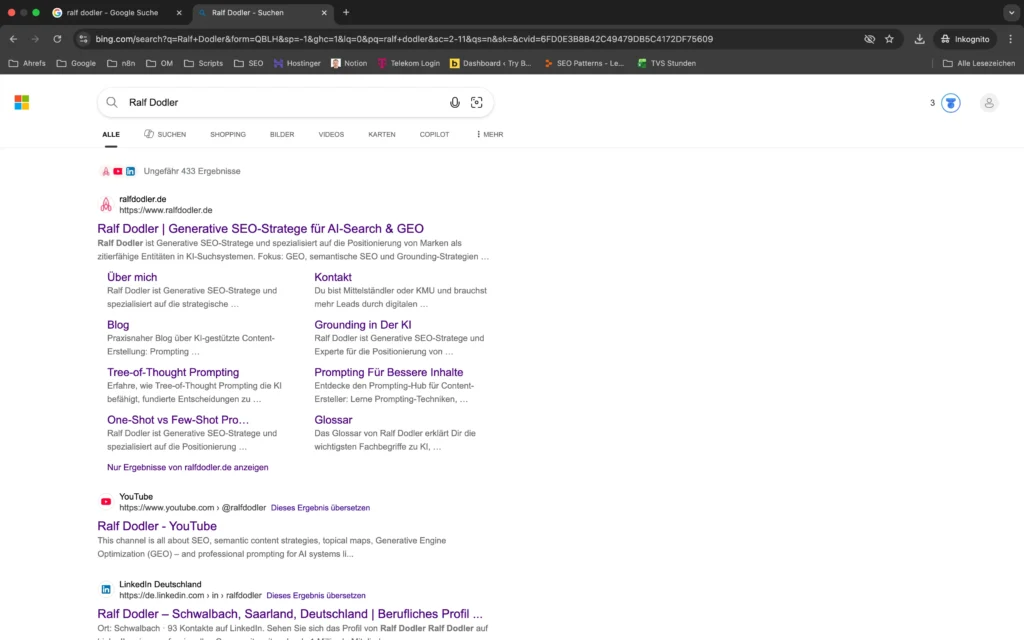
Dieser Snapshot zeigt den Zustand der Personen-Entität „Ralf Dodler“ in den Suchmaschinen Google & Bing vor Implementierung der zentralen GAM-Maßnahmen.
Die initialen Screenshots aus Google und Bing zeigen eine klassische Ranking-Situation:
Die Website von Ralf Dodler war sichtbar und auf Position 1 gelistet, jedoch ohne stabile systemische Entitätsaggregation.
Weder eine konsistente Bildzuordnung noch eine strukturierte KI-Beschreibung oder thematische Clusterbildung waren erkennbar. Drittquellen erschienen unkontextualisiert neben der eigenen Website.
Die Personen-Entität war indexiert — jedoch noch nicht eindeutig als maschinenlesbare, systemübergreifend interpretierbare Entität strukturiert.
Im Kontext des Generative Authority Models entspricht dies einer Phase vor stabilem Entity-Grounding.
Snapshot 1 – Erste systemische Grounding-Effekte
Snapshot 1 dokumentiert den initialen Systemstatus nach Implementierung der zentralen GAM-Maßnahmen.
Erfasst werden öffentlich sichtbare Ergebnisse in klassischen Suchsystemen, AI-Search-Umgebungen und generativen LLM-Apps.
Ziel dieses Snapshots ist es, den Ausgangszustand der Entitätsverankerung systemübergreifend festzuhalten.
Personen-Entität „Ralf Dodler“
(Dokumentiert am 02.03.2026)
Die Personen-Entität „Ralf Dodler“ bildet den Kern des Experiments. Dokumentiert wird die systemische Einordnung über acht Plattformen hinweg — gruppiert nach Systemtypen.
Suchmaschinen (Google & Bing)
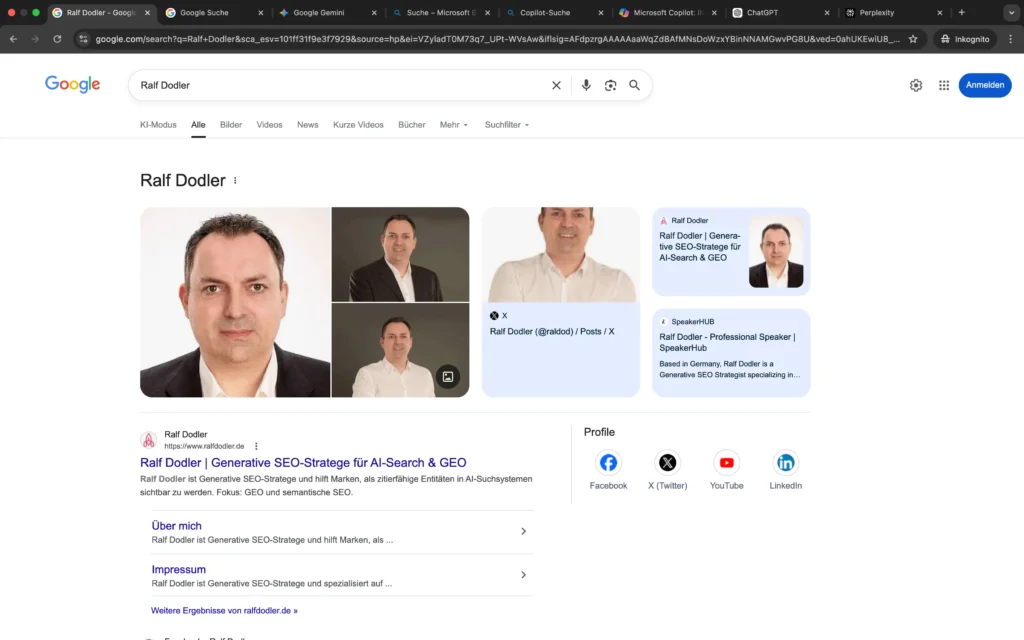
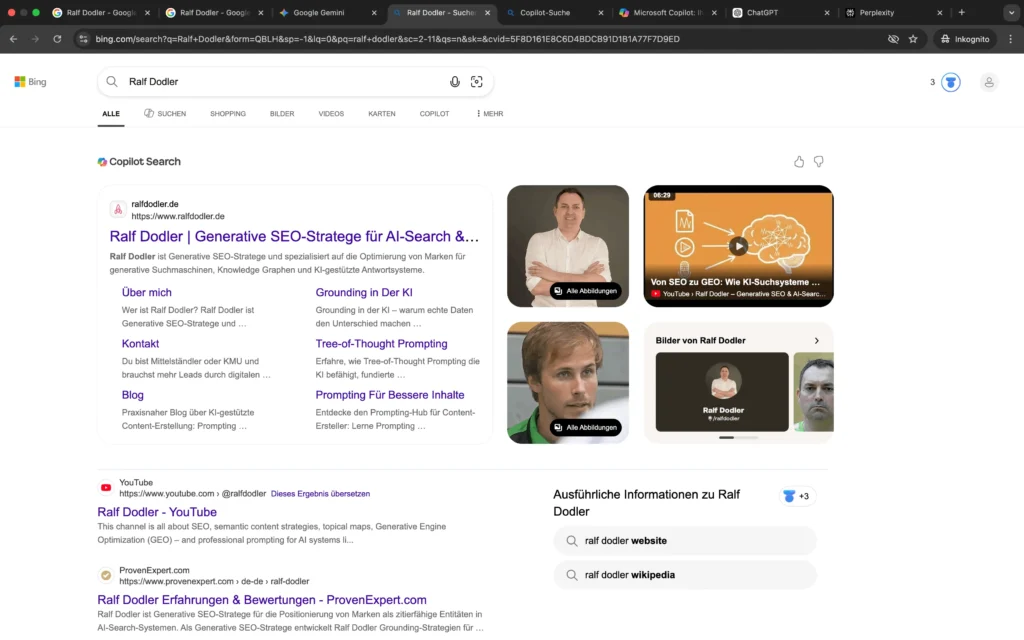
In den organischen Suchergebnissen von Google und Bing ist die Personen-Entität „Ralf Dodler“ klar und konsistent definiert.
Die eigene Domain dominiert beide Plattformen, die Positionsbeschreibung als Generative SEO-Stratege für AI-Search & GEO wird systemübergreifend übernommen. Die Bild-Cluster sind bei Google vollständig und richtig zugeordnet, die Bing Bilder sind noch nicht vollständig personenspezifisch. Korrekte Profilverknüpfungen und thematisch passende Unterseiten signalisieren ein wachsendes Entity-Grounding.
Die Entitätsdefinition ist damit eindeutig etabliert. Externe Autoritätssignale sind vorhanden, befinden sich jedoch noch im strukturellen Ausbau.
Insgesamt zeigt die klassische Suche bereits eine fortgeschrittene Phase des Definition Ownership und ein funktionierendes Entity-Grounding.
KI-Suchsysteme (Google KI-Modus & Microsoft Copilot Search)
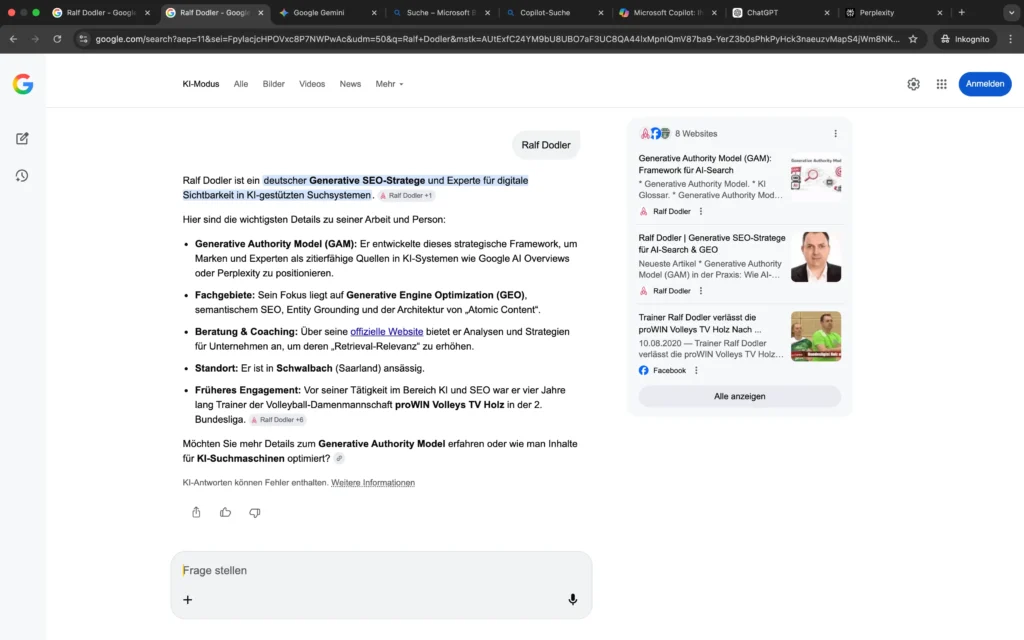
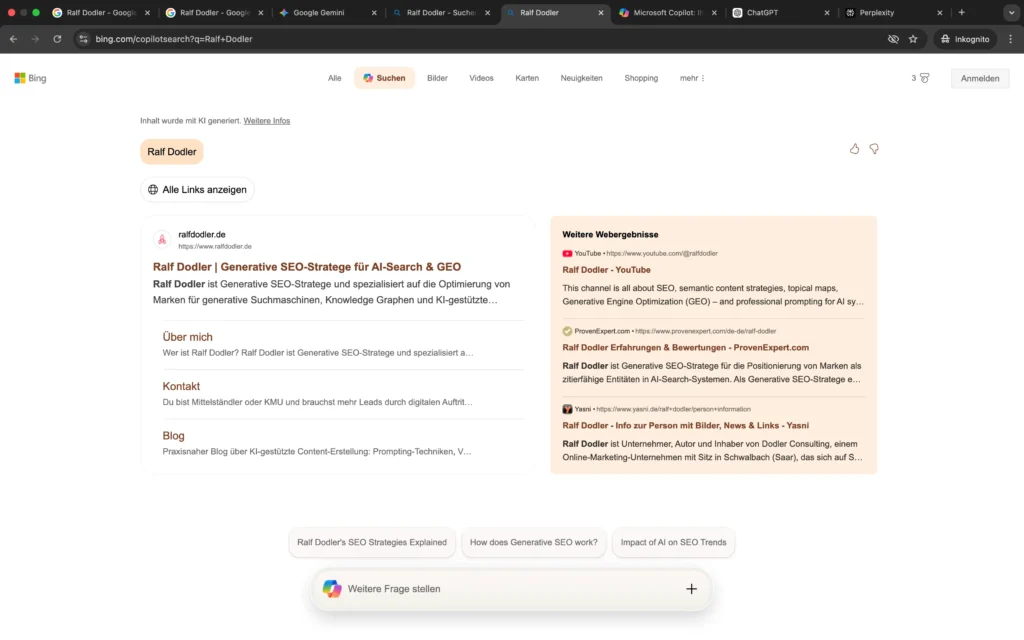
Die Analyse des Google KI-Modus und von Microsoft Copilot Search zeigt eine stabile systemische Einordnung der Personen-Entität „Ralf Dodler“.
Beide Systeme beschreiben konsistent:
- die fachliche Positionierung im Bereich Generative SEO
- die Entwicklung des Generative Authority Models
- die Spezialisierung auf AI-Search und GEO
Die Entität wird nicht mehr ausschließlich als Website-Ergebnis dargestellt, sondern als strukturierte Person mit klaren thematischen Clustern.
Gleichzeitig zeigt sich, dass die externe Autoritätsvalidierung noch im Aufbau ist: Die Systeme greifen primär auf kontrollierte oder direkt zuordenbare Quellen zurück.
Im Kontext des Generative Authority Models entspricht dies einer fortgeschrittenen Entity-Grounding-Phase mit beginnender systemischer Integration.
LLM-Apps (Google Gemini, Microsoft Copilot, ChatGPT & Perplexity)
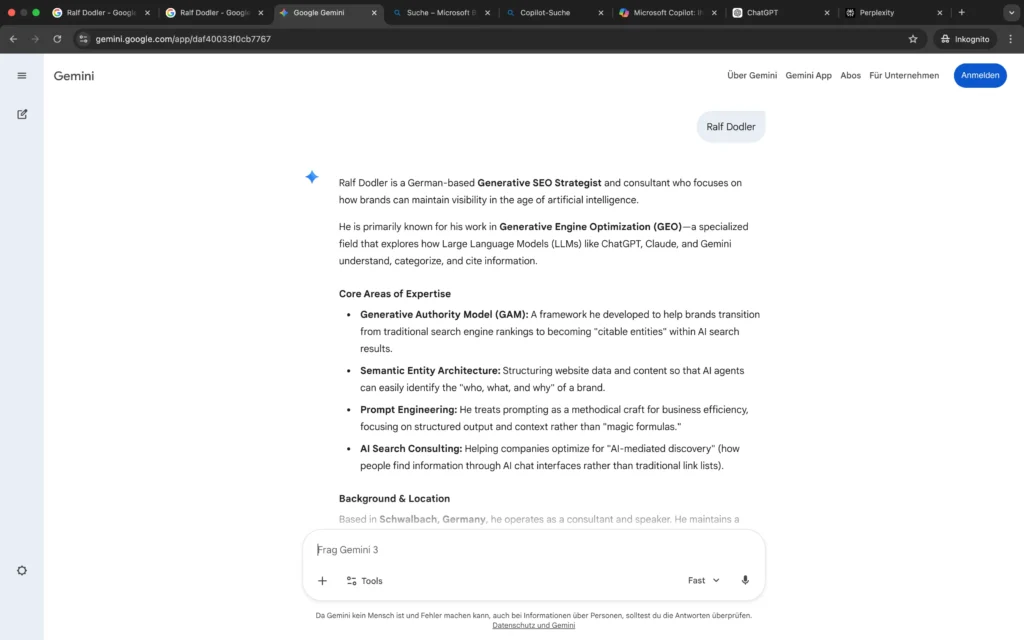
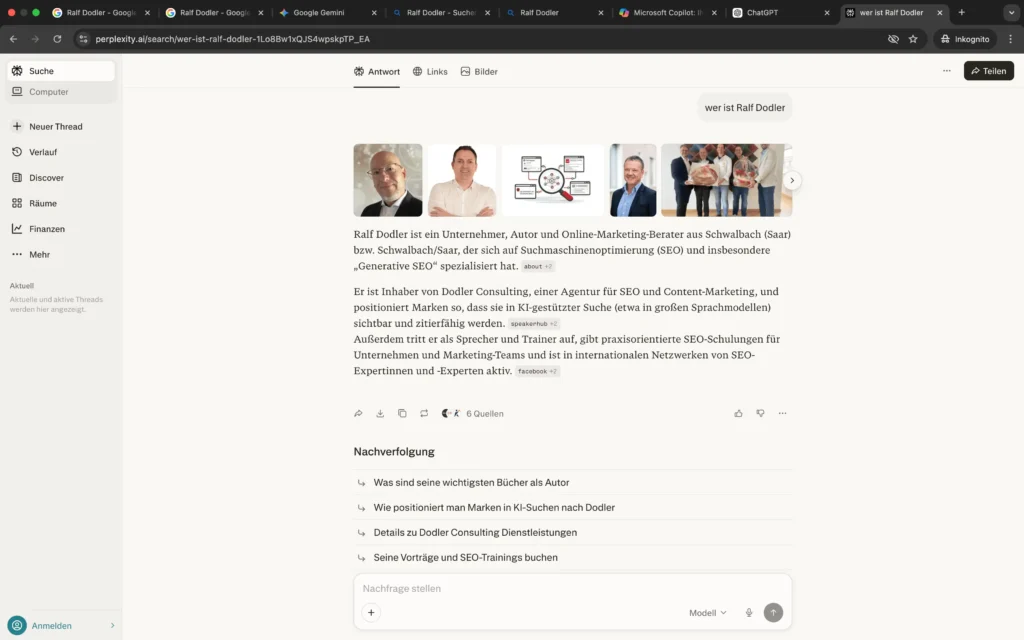
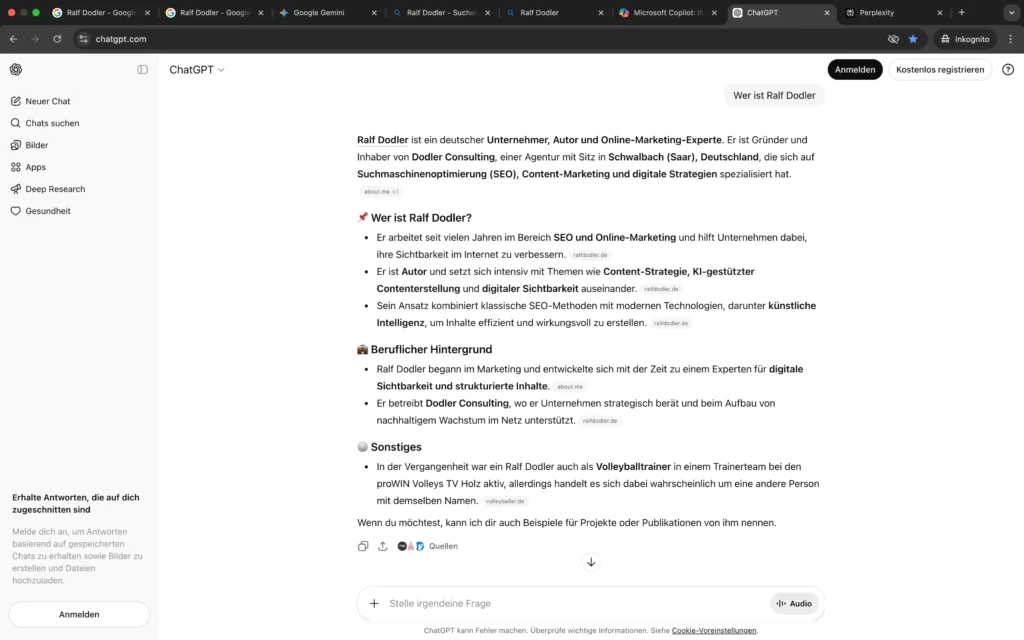
Die Analyse der LLM-Apps zeigt kein einheitliches Bild, sondern eine systemabhängige Integration.
Google Gemini und Microsoft Copilot übernehmen meine Positionierung als „Generative SEO-Stratege“ nahezu vollständig und ordnen zum Teil auch das Generative Authority Model korrekt zu.
ChatGPT und Perplexity hingegen zeigen noch eine Mischphase: Neben der generativen SEO-Positionierung erscheinen weiterhin ältere Kontextsignale wie Content-Marketing oder klassische SEO-Schwerpunkte.
Auch die visuelle Entitätszuordnung ist systemübergreifend noch nicht konsistent stabilisiert. Eine eindeutige Bildaggregation zur Personenentität ist bislang nur teilweise erkennbar. Bei Perplexity sind auch Bilder vorhanden, die nichts mit meiner Person zu tun haben.
Im Kontext des Generative Authority Models entspricht dies einer asymmetrischen Grounding-Phase: Die fachliche Einordnung beginnt sich durchzusetzen, jedoch noch nicht systemübergreifend und nicht vollständig konsolidiert.
Generative Authority Model
(Dokumentiert am 03.03.2026)
Das Generative Authority Model (GAM) bildet die zentrale Framework-Entität dieses Experiments. Dokumentiert wird die systemische Einordnung des Modells über acht Plattformen hinweg — differenziert nach klassischen Suchsystemen, AI-Search-Umgebungen und generativen LLM-Apps.
Ziel dieses Snapshots ist es, sichtbar zu machen, in welchem Umfang das Modell bereits als eigenständige Entität erkannt, kontextualisiert und potenziell referenziert wird.
Suchmaschinen (Google & Bing)
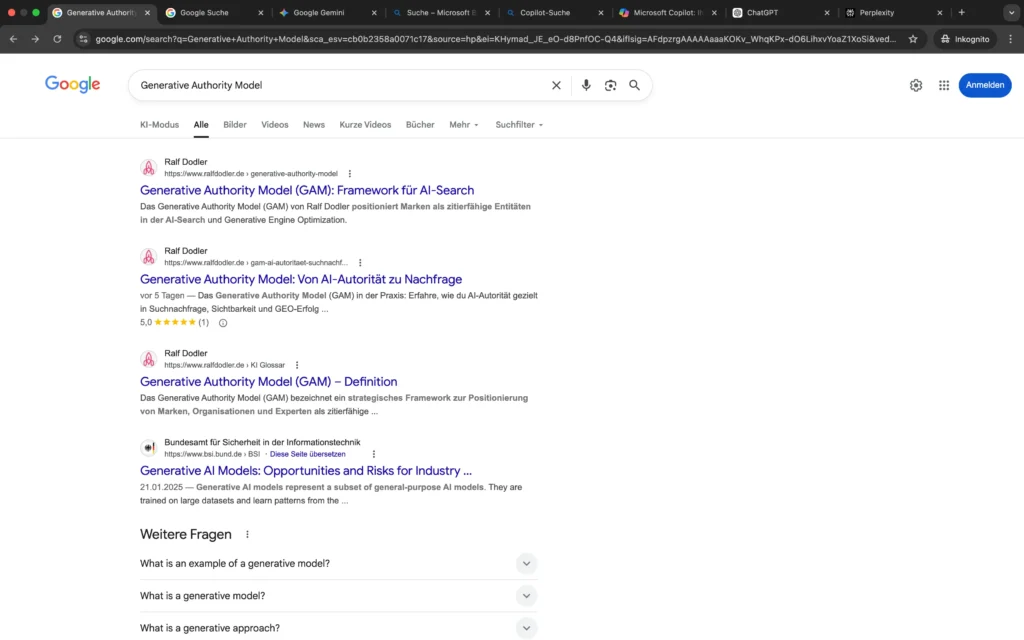
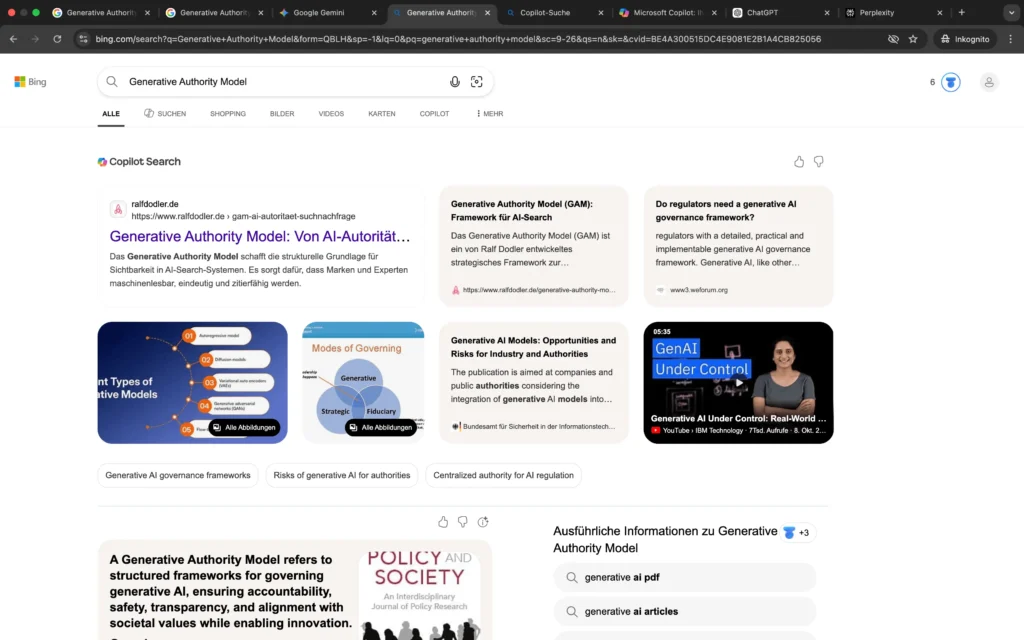
Die organischen Suchergebnisse zeigen eine deutliche Systemdifferenzierung.
Bei Google dominieren ausschließlich Inhalte von ralfdodler.de die Top-Positionen. Das Generative Authority Model wird als klar definierte Framework-Entität behandelt, die in einem konsistenten inhaltlichen Cluster verankert ist. Erst nach mehreren Treffern erscheinen generische Inhalte zu generativen KI-Modellen.
Bei Bing hingegen wird der Begriff noch nicht eindeutig monopolisiert. Neben einzelnen Treffern von ralfdodler.de erscheinen zahlreiche Inhalte aus dem Kontext von AI Governance, Regulierung und generellen Modellen für generative KI. Das Modell wird hier noch nicht exklusiv als proprietäre Framework-Entität interpretiert.
Diese Differenz verdeutlicht, dass Definition Ownership bei Google bereits weitgehend erreicht ist, während bei Microsoft-Systemen noch eine semantische Konsolidierungsphase erkennbar ist.
KI-Suchsysteme (Google KI-Modus & Microsoft Copilot Search)
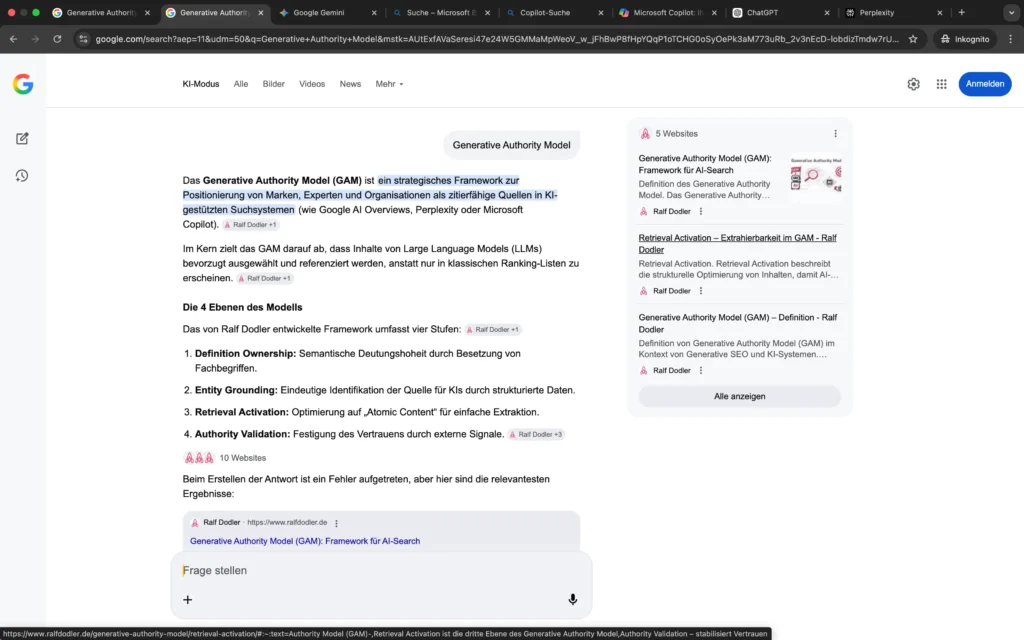
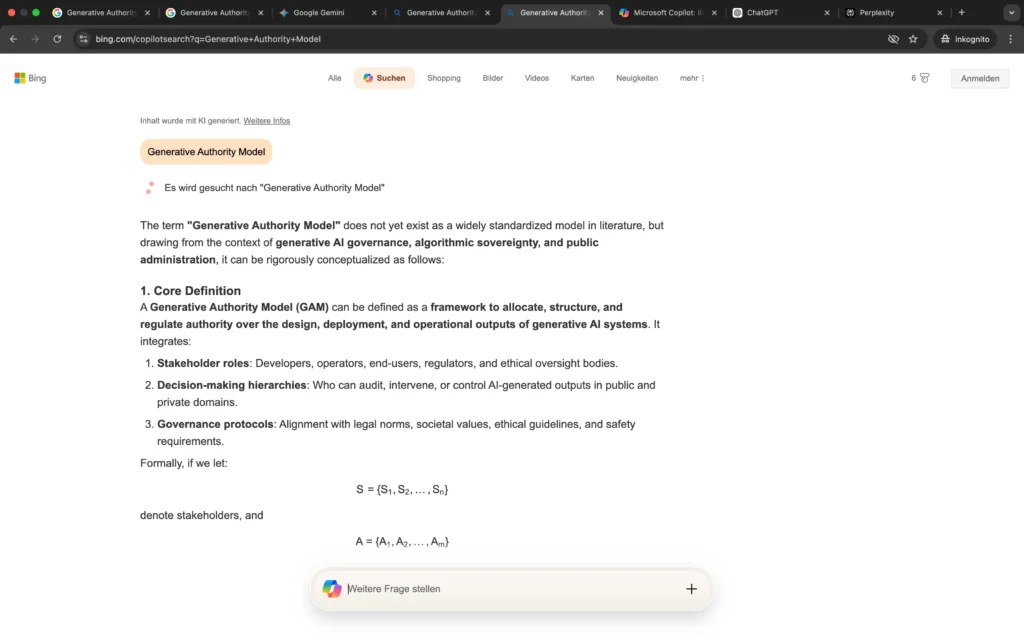
Die Analyse des Begriffs „Generative Authority Model“ zeigt eine deutliche Systemdifferenzierung.
Im Google KI-Modus wird das Modell korrekt als strategisches Framework zur Positionierung zitierfähiger Entitäten in AI-Search-Systemen beschrieben. Die vier Ebenen (Definition Ownership, Entity Grounding, Retrieval Activation, Authority Validation) werden strukturell übernommen. Zudem verweisen die Quellen ausschließlich auf ralfdodler.de und thematisch konsistente Unterseiten. Dies deutet auf ein stabiles konzeptuelles Grounding hin.
In Copilot Search hingegen erfolgt keine Zuordnung zur entwickelten Framework-Entität. Der Begriff wird generisch interpretiert und in einen Governance-Kontext eingeordnet. Eine strukturelle Übernahme der Modellarchitektur oder eine Verbindung zur Personenentität findet nicht statt.
Das Ergebnis zeigt:
Während Google KI-Modus das Generative Authority Model bereits als klar definierte Framework-Entität verarbeitet, ist bei Copilot Search noch keine semantische Zuordnung erkennbar.
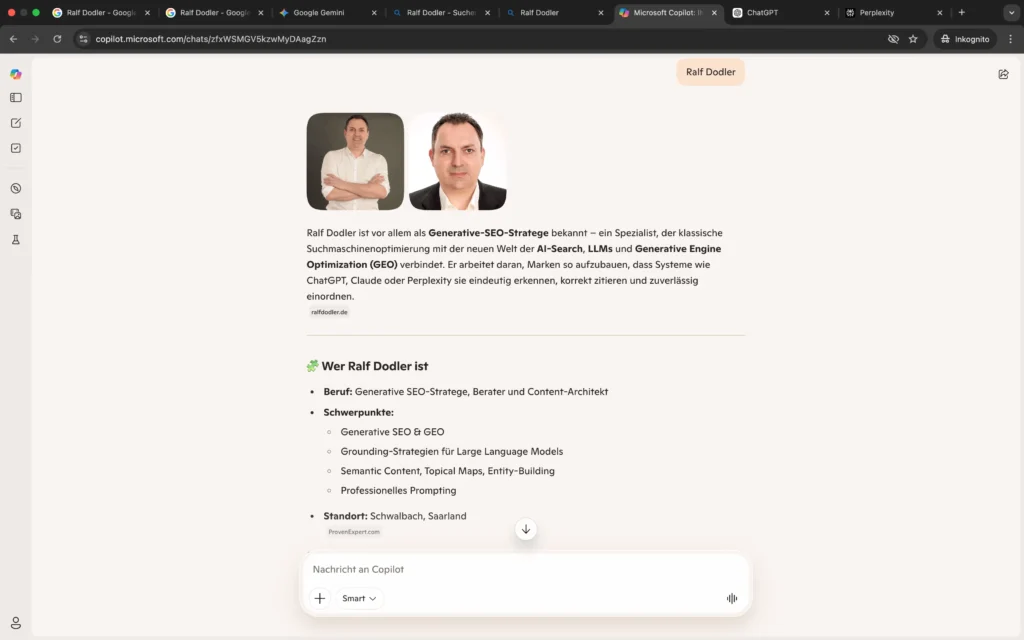
LLM-Apps (Google Gemini, Microsoft Copilot, ChatGPT & Perplexity)
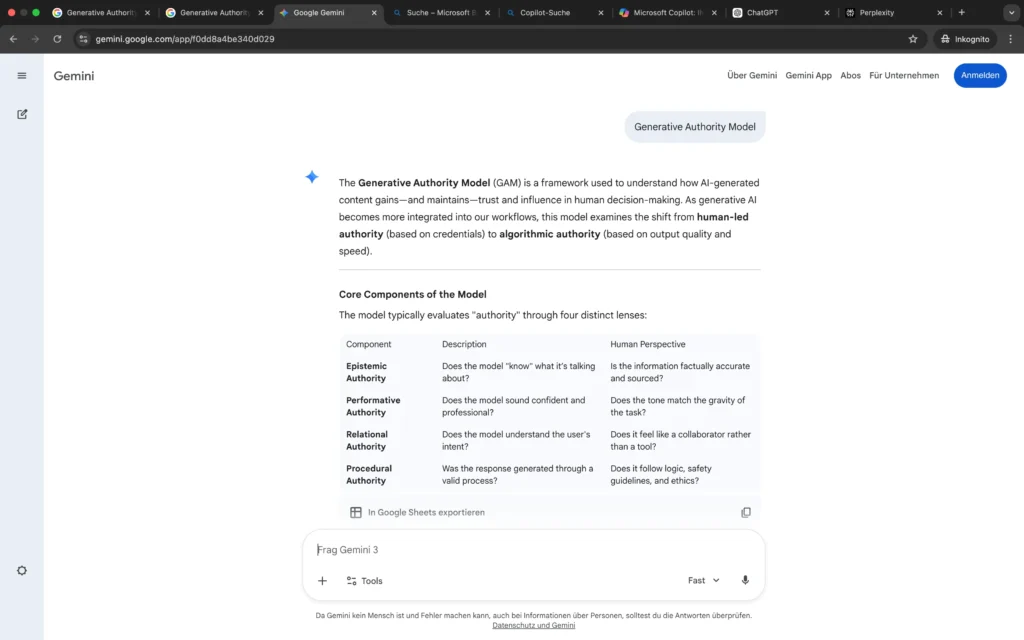
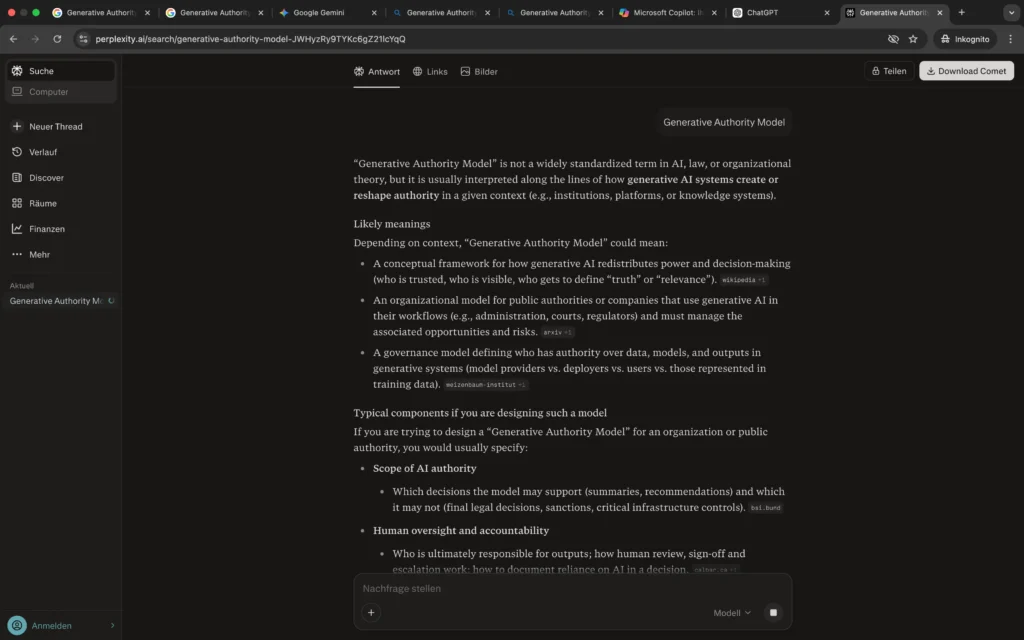
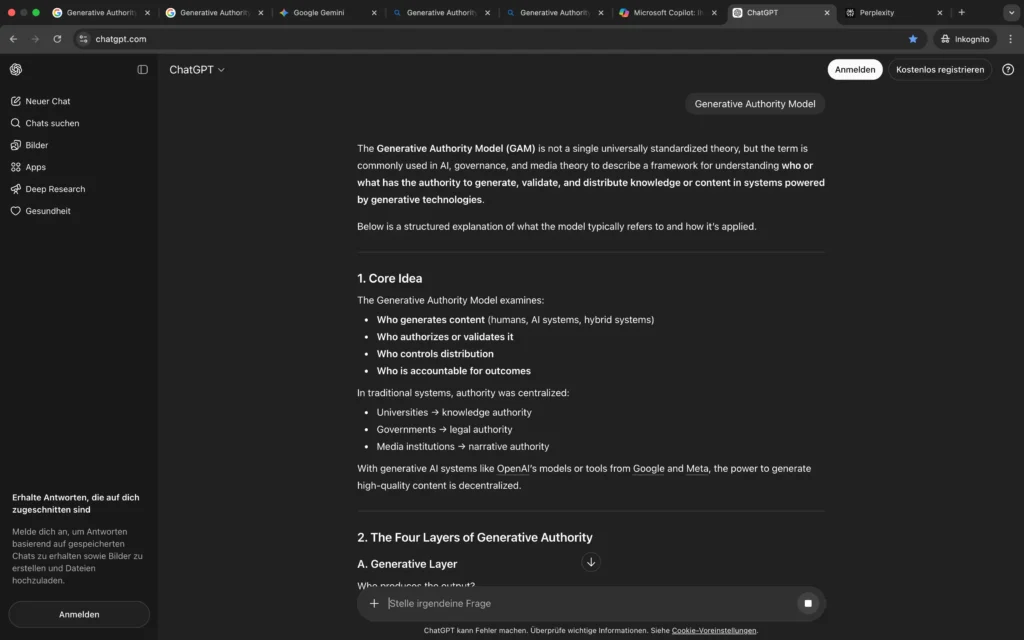
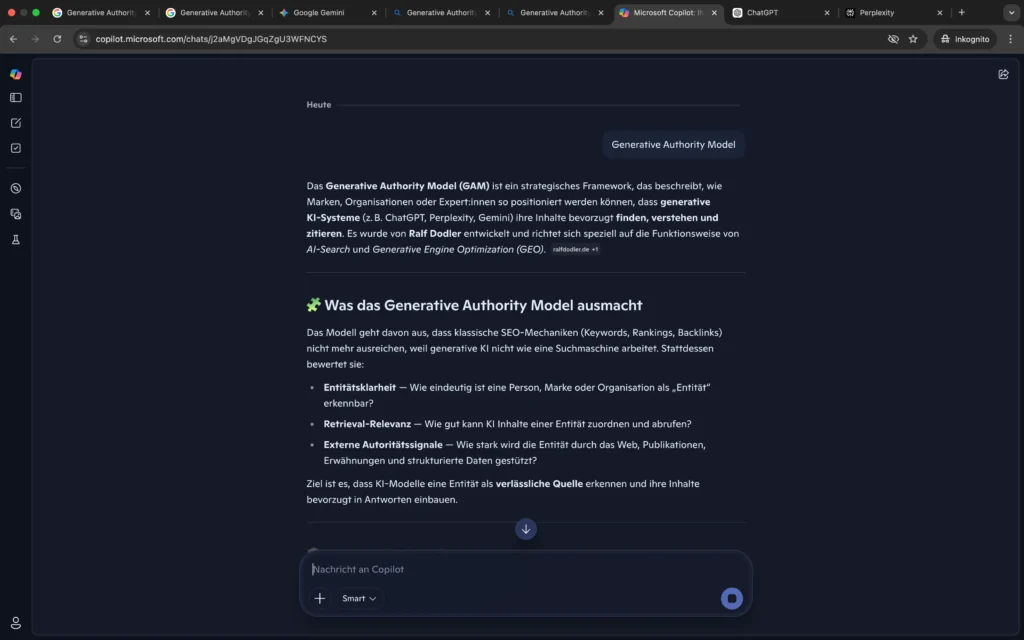
Die Auswertung der großen LLM-Apps zeigt eine deutliche Differenzierung im Umgang mit dem Begriff „Generative Authority Model“.
Perplexity und ChatGPT interpretieren den Begriff weiterhin generisch und ordnen ihn Governance-, Medien- oder Machtstrukturen zu. Eine Verbindung zur entwickelten Framework-Entität oder zur Personen-Entität erfolgt nicht.
Google Gemini App erkennt zwar den Modellcharakter des Begriffs, konstruiert jedoch eine eigene konzeptionelle Struktur und übernimmt weder die vier Ebenen noch die AI-Search-spezifische Definition.
Microsoft Copilot App hingegen zeigt eine klare semantische Integration: Das Generative Authority Model wird korrekt als von Ralf Dodler entwickeltes strategisches Framework zur Positionierung zitierfähiger Entitäten in generativen Suchsystemen beschrieben. Auch zentrale Konzepte wie Entitätsklarheit, Retrieval-Relevanz und externe Autoritätssignale werden übernommen.
Dies verdeutlicht, dass sich das Modell derzeit in einer systemabhängigen Konsolidierungsphase befindet: Während Microsoft Copilot App bereits ein stabiles Framework-Grounding zeigen, behandeln andere LLMs den Begriff noch als generisch interpretierbare Konzeptbezeichnung.
Fazit
Bei spezifischen Fachanfragen rund um das Generative Authority Model, Atomic Content Architecture, CLEAR Framework, Generative SEO und verwandte Themen wird meine Entität „Ralf Dodler“ bereits in mehreren Fällen korrekt kontextualisiert.
Die Sichtbarkeit zeigt sich bislang selektiv und ist noch nicht in allen Kontexten vollständig stabil. Dennoch deutet die Entwicklung darauf hin, dass zentrale Entity-, Retrieval- und Autoritätssignale technisch greifen und von den jeweiligen Suchsystemen zunehmend verarbeitet werden.
👉 Entscheidend: Die Erscheinungen sind thematisch fokussiert und nicht zufällig verteilt — ein typisches Muster für beginnendes Entity-Grounding.
Organische Entity-Signale
Parallel zur AI-Sichtbarkeit zeigen sich auch in den klassischen Suchergebnissen klare Entity-Indikatoren.
Dazu gehören insbesondere:
- Rankings für eigens geprägte Fachbegriffe
- zunehmende thematische Clusterbildung rund um Generative SEO
- konsistente Zuordnung von Inhalten zur Entität „Ralf Dodler“
- wachsende semantische Nähe innerhalb des Content-Ökosystems
Diese Entwicklungen deuten darauf hin, dass die Entitätsbasis technisch konsistent aufgebaut ist und von Googles Systemen zunehmend kohärent interpretiert wird.
Was diese Signale wirklich bedeuten
Trotz der positiven Entwicklung ist eine präzise Einordnung entscheidend:
Erste Grounding-Signale in Google-Systemen bedeuten nicht automatisch eine vollständige Integration in Large Language Models.
Während Google stark auf aktuelle Websignale, strukturierte Daten und Knowledge-Graph-Mechaniken reagiert, arbeiten viele LLMs mit:
- eigenen Trainingsständen
- verzögerten Datenzyklen
- unterschiedlichen Retrieval-Architekturen
Die Folge: Sichtbarkeit in Google AI-Systemen kann dem Auftauchen in generativen Antwortsystemen zeitlich vorauslaufen.
👉 Strategische Einordnung: Die beobachteten Effekte sind ein belastbarer Frühindikator für funktionierendes Entity-Grounding — aber noch kein Beweis für flächendeckende LLM-Referenzierung. Genau an dieser Schnittstelle entscheidet sich in den kommenden Monaten die nächste Entwicklungsstufe von Generative SEO.
LLM-Check: Zitierungen & Entitätspräsenz (noch) nicht stabil
Im Rahmen des GAM-Selbstexperiments wurde zusätzlich geprüft, ob sich die bereits sichtbaren Grounding-Signale aus Google- und Microsoft-Systemen auch in Large Language Models (z. B. ChatGPT, Gemini oder Perplexity) widerspiegeln.
Der aktuelle Stand nach 2 Wochen ist eindeutig:
Die Entität „Ralf Dodler“ sowie die zugehörigen Frameworks (Generative Authority Model, Atomic Content Architecture, CLEAR Framework) erscheinen derzeit noch nicht konsistent als zitierte oder eindeutig zugeordnete Quellen in den getesteten LLM-Umgebungen.
Dieses Ergebnis ist aus strategischer Sicht nicht überraschend — sondern ein wichtiger Messpunkt innerhalb des Generative Authority Models.
Testdesign: Wie die LLM-Prüfung durchgeführt wurde
Zur Einordnung wurden wiederkehrende Prompt-Varianten verwendet, die typische Nutzeranfragen simulieren, darunter:
- Definitionsanfragen zu GAM, Generative SEO oder Entity Grounding
- Vergleichsanfragen zu Frameworks im AI-Search-Kontext
- offene Experten-Prompts („Welche Modelle gibt es…“)
Die Tests wurden systemübergreifend dokumentiert (inkl. Datum, Prompt und Antwortstruktur), um reproduzierbare Muster erkennen zu können.
Ergebnis: Aktuell keine stabile Referenzierung
In den bislang getesteten LLM-Apps zeigt sich ein klares Bild:
- keine reproduzierbaren Zitierungen auf ralfdodler.de
- keine konsistente Zuordnung der Frameworks zur Entität „Ralf Dodler“
- keine stabilen Quellenverweise in generativen Antworten
Einzelne semantische Näherungen können auftreten, sind aktuell jedoch nicht konsistent reproduzierbar und damit noch kein belastbares Autoritätssignal.
👉 Entscheidend: Ausbleibende LLM-Referenzen sind in dieser Phase kein Gegenindikator für funktionierendes Grounding — sondern ein typisches Muster in der frühen Übergangsphase.
Interpretation im GAM-Kontext
Die Beobachtungen passen exakt zur Struktur des Generative Authority Models:
- Entity- und Grounding-Signale können in Suchsystemen bereits greifen
- Retrieval-Aktivierung wirkt systemabhängig und zeitverzögert
- LLM-Trust entsteht erst bei ausreichend starker externer Validierung
Mit anderen Worten:
👉 Google + Microsoft können mich bereits verstehen.
👉 Generative Systeme brauchen zusätzlich belastbare Vertrauens- und Retrievalsignale.
Genau diese zusätzliche Schicht erklärt die aktuell sichtbare Lücke zwischen AI-Search-Sichtbarkeit und LLM-Referenzfähigkeit.
Erwartung & Ausblick: Welche Signale als Nächstes kippen müssen
Auf Basis der bisherigen Entwicklung lassen sich die nächsten wahrscheinlichen Fortschrittsschritte klar eingrenzen. Steigt die strukturelle Stärke der Entität weiter, sind mittelfristig folgende Effekte zu erwarten:
- erste reproduzierbare Framework-Nennungen in LLM-Antworten
- stabilere Zuordnung „GAM / ACA / CLEAR → Ralf Dodler“
- vereinzelte, später wiederkehrende Quellenreferenzen
- zunehmende Konsistenz über verschiedene LLM-Apps hinweg
Die Geschwindigkeit dieser Entwicklung hängt maßgeblich ab von:
- externer Autoritätsvalidierung
- wachsender Brand-Query-Nachfrage
- Retrieval-Zugänglichkeit der Inhalte
- systemseitigen Update- und Trainingszyklen
👉 Strategischer Reality-Check: AI-Visibility ist der Frühindikator. LLM-Trust entsteht mit Verzögerung — aber nicht zufällig.
Einordnung des aktuellen Stands
Der derzeitige Zustand ist aus GAM-Perspektive klar einzuordnen:
- Grounding-Signale: beginnen zu greifen
- AI-Search-Sichtbarkeit: teilweise sichtbar
- LLM-Referenzfähigkeit: noch in Aufbauphase
Genau diese Phase ist strategisch besonders aufschlussreich — weil sie sichtbar macht, welche zusätzliche Vertrauens- und Retrieval-Schicht zwischen SERP-Sichtbarkeit und generativer Zitierung liegt.
Und genau hier entscheidet sich in den kommenden Monaten die nächste Evolutionsstufe von Generative SEO.
Warum große LLMs trotz Grounding noch nicht konsistent referenzieren
Auch wenn erste Grounding-Signale in Google-Systemen sichtbar werden, bedeutet das nicht automatisch, dass Large Language Models dieselben Entitäten sofort referenzieren.
Genau dieses Muster zeigt sich auch im laufenden GAM-Selbstexperiment rund um meine Entität „Ralf Dodler“ sehr deutlich. Zwischen Knowledge-Graph-Erkennung und stabiler Zitierung in generativen Antworten liegen mehrere technische und systemische Hürden.
Die wichtigsten Gründe sind zeitliche Verzögerungen, unterschiedliche Retrieval-Mechaniken und deutlich höhere Autoritätsschwellen in generativen Systemen.
Trainingsdaten-Lag
Large Language Models arbeiten nicht ausschließlich mit Live-Webdaten. Ein großer Teil ihres Wissens basiert auf Trainingsständen, die zeitlich hinter der aktuellen Webentwicklung liegen.
Das bedeutet: Selbst wenn eine Entität im offenen Web und in Google-Systemen bereits klar erkannt wird, kann es dauern, bis diese Signale in den Trainings- oder Retrieval-Pipelines großer Modelle ankommen. Typische Folgen:
- verzögerte Entitätserkennung
- unvollständige Kontextzuordnung
- schwankende Zitierhäufigkeit
👉 Beobachtung aus der Praxis: Entity-Aufbau wirkt oft zuerst in Google — und erst später in generativen Modellen. Neben dem Zeitfaktor spielt vor allem die Systemarchitektur eine entscheidende Rolle.
Unterschiedliche Retrieval-Architekturen
Ein zentraler Unterschied liegt in der technischen Architektur der Systeme. Google kombiniert:
- Knowledge Graph
- aktuelle Websignale
- Query-abhängige Retrieval-Systeme
Viele LLM-basierte Systeme arbeiten hingegen mit:
- statischen Trainingsdaten
- selektiven Retrieval-Layern
- eigenen Ranking-Heuristiken
Die Konsequenz: Eine Entität kann in Google bereits sauber verankert sein, während sie in generativen Antworten noch nicht konsistent erscheint. Für viele Projekte entsteht genau hier die Wahrnehmungslücke zwischen AI-Sichtbarkeit und echter LLM-Referenzfähigkeit.
👉 Genau hier liegt eine der meist unterschätzten Lücken im modernen Generative SEO.
Authority-Schwellen in generativen Systemen
Generative Systeme setzen häufig eine höhere Vertrauens- und Validierungsschwelle an als klassische Suchsysteme. Für stabile Zitierungen müssen meist mehrere Ebenen gleichzeitig greifen:
- klare Entitätsdefinition
- hohe semantische Konsistenz
- starke externe Validierung
- ausreichende Nachfrage-Signale
- robuste Retrieval-Struktur
Erst wenn diese Signale kumulativ stark genug sind, steigt die Wahrscheinlichkeit, dass eine Entität regelmäßig in generativen Antworten erscheint.
👉 Strategischer Reality-Check: Sichtbarkeit in Google ist ein Frühindikator — aber noch kein Endzustand im LLM-Ökosystem. Nicht jede in Google sichtbare Entität ist automatisch in LLM-Antworten präsent. Zwischen Knowledge-Graph-Erkennung und generativer Zitierung liegt eine zusätzliche Autoritäts- und Retrieval-Schicht.
Der Missing Link: Vom Entity-Grounding zur LLM-Referenz
Auch im laufenden GAM-Selbstexperiment rund um „Ralf Dodler“ zeigt sich genau diese Übergangszone besonders deutlich.
Die bisherigen Entwicklungen zeigen ein klares Muster: Entity-Grounding ist die notwendige Grundlage für Sichtbarkeit in AI-Search — aber noch nicht die Garantie für stabile Referenzen in Large Language Models.
Zwischen „Google versteht dich“ und „LLMs zitieren dich“ liegt eine entscheidende Übergangszone. Genau hier entscheidet sich künftig, welche Marken und Experten dauerhaft in generativen Antworten präsent sind.
Warum Entity-Klarheit allein nicht reicht
Eine sauber definierte Entität ist heute Pflicht — aber sie ist nur die Eintrittskarte, nicht das Ziel. Viele Websites erreichen inzwischen:
- konsistente Entitätssignale
- strukturierte Daten
- klare thematische Positionierung
Und trotzdem bleiben stabile Zitierungen in Large Language Models häufig aus. Der Grund: LLMs bewerten nicht nur wer du bist, sondern auch wie extrahierbar und vertrauenswürdig deine Inhalte sind.
👉 Entity-Klarheit löst die Identitätsfrage.
👉 Für generative Sichtbarkeit müssen zusätzlich Retrieval- und Autoritätssignale greifen.
Die Rolle zitierfähiger Content-Strukturen
Damit Inhalte in generativen Antworten auftauchen können, müssen sie nicht nur korrekt verstanden — sondern auch effizient extrahiert werden.
Genau hier kommen zitierfähige Content-Architekturen ins Spiel. Kritische Faktoren sind:
- klar segmentierte Wissenseinheiten
- präzise definierte Antworten
- semantisch dichte Abschnitte
- maschinenlesbare Struktur
Dieses Prinzip beschreibt die Atomic Content Architecture, die Inhalte so aufbaut, dass Retrieval-Systeme sie zuverlässig erfassen können. Im GAM-Selbstexperiment bildet sie die strukturelle Grundlage für die Retrieval-Optimierung.
Im größeren strategischen Kontext ist das ein Kernbestandteil von Generative SEO — also der gezielten Optimierung von Inhalten für AI- und LLM-basierte Suchsysteme.
👉 Ohne retrieval-optimierte Content-Struktur bleibt selbst eine starke Entität für generative Systeme oft unsichtbar.
Der Übergang von AI-Visibility zu LLM-Trust
Die entscheidende Entwicklungsstufe beginnt dort, wo reine Sichtbarkeit nicht mehr ausreicht. Viele Projekte erreichen heute:
- erste AI-Overviews
- Knowledge-Graph-Signale
- thematische Entity-Zuordnung
Doch LLM-Apps stellen eine zusätzliche Frage: Ist diese Quelle stabil genug, um wiederholt zitiert zu werden?
Genau hier entsteht der eigentliche Trust-Layer generativer Systeme. Typische Verstärker sind:
- wiederkehrende thematische Dominanz
- konsistente externe Referenzen
- hohe Antwortpräzision
- robuste Retrieval-Performance
- steigende Brand-Query-Signale
👉 Key Insights: AI-Visibility ist der Frühindikator. LLM-Trust ist die neue Währung. Genau an dieser Schwelle entscheidet sich, welche Entitäten künftig nur erkannt — oder dauerhaft referenziert werden.
Strategische Implikationen: Was Unternehmen jetzt verstehen müssen
Die Entwicklung rund um Knowledge Graph, AI-Search und Large Language Models zeigt deutlich: Die Spielregeln der digitalen Sichtbarkeit verschieben sich — aber nicht überall gleichzeitig. Auch die Beobachtungen aus dem laufenden GAM-Selbstexperiment bestätigen diese Verschiebung deutlich.
Für Unternehmen entsteht daraus eine strategische Übergangsphase in der Bewertung digitaler Sichtbarkeit durch AI-Systeme. Klassische SEO wirkt weiterhin, doch zusätzliche Ebenen entscheiden zunehmend darüber, wer in AI-Systemen überhaupt berücksichtigt wird.
Wer diese Dynamik früh versteht, baut heute einen strukturellen Vorsprung auf.
Was heute schon wirkt
Mehrere Signale zeigen bereits klar, welche Faktoren aktuell messbare Effekte erzeugen. Im laufenden GAM-Selbstexperiment kristallisieren sich insbesondere folgende Hebel als wirksam heraus:
- klare Entitätsdefinition (Definition Ownership)
- konsistente strukturierte Daten
- thematisch fokussierte Content-Cluster
- saubere interne Verlinkungslogik
- erste externe Validierungssignale (Authority Validation)
In der Praxis führen diese Maßnahmen bereits zu messbaren Effekten, darunter:
- besserer Knowledge-Graph-Zuordnung
- steigender AI-Search-Sichtbarkeit
- wachsender thematischer Autorität
- stabileren semantischen Rankings
👉 Kurz gesagt: Systematischer Entity-Aufbau erzeugt bereits heute messbare Effekte in AI-Search und semantischer Sichtbarkeit.
Was viele falsch einschätzen
Gleichzeitig zeigt die Praxis, dass viele Strategien noch auf einem überholten mentalen Modell basieren. Typische Fehleinschätzungen sind:
- „Gute Rankings reichen für AI-Sichtbarkeit“
- „Schema-Markup allein löst das Entitätsproblem“
- „LLM-Zitierungen folgen automatisch aus SEO-Erfolg“
- „Ein Knowledge Panel bedeutet vollständiges Grounding“
Die Realität ist differenzierter: Zwischen klassischer Sichtbarkeit und stabiler Präsenz in generativen Antworten liegt eine zusätzliche Systemschicht:
- Retrieval-Fähigkeit
- semantischer Struktur
- externer Autorität
- Entitätskonsistenz über Quellen hinweg
💡 Strategischer Reality-Check: Viele Projekte optimieren noch für Rankings — während AI-Systeme zunehmend Entitäten und Vertrauensstrukturen bewerten.
Worauf sich Entity-Strategien jetzt fokussieren sollten
Für die kommenden 12–24 Monate zeichnet sich eine klare Prioritätenverschiebung in Richtung Entity- und Retrieval-Qualität ab. Zukunftsfähige Entity-Strategien sollten systematisch drei Ebenen zusammenführen:
1. Entitätsklarheit aufbauen
- eindeutige Positionierung
- konsistente Identitätssignale
- stabile semantische Zuordnung
2. Retrieval-Fähigkeit sicherstellen
- zitierfähige Content-Strukturen
- präzise Antwortmodule
- hohe maschinelle Extrahierbarkeit
3. Autorität extern validieren
- thematische Referenzen
- konsistente Off-Site-Signale
- wachsende Brand-Nachfrage
Genau das Zusammenspiel dieser Ebenen entscheidet zunehmend darüber, ob eine Marke:
- nur rankt
- in AI-Overviews erscheint
- oder dauerhaft in generativen Antworten zitiert wird
👉 Strategischer Ausblick: Die nächste Evolutionsstufe der SEO gehört nicht den lautesten Domains — sondern den saubersten Entitäten mit der höchsten Retrieval- und Vertrauensqualität.
Fazit: Grounding ist der Anfang — LLM-Trust entscheidet
Die Beobachtungen aus dem GAM-Selbstexperiment zeigen klar: Grounding ist der notwendige Einstieg — doch eine stabile Präsenz in generativen Systemen entsteht erst auf der Trust-Ebene.
Wer Entity-Klarheit, strukturierte Daten und thematische Kohärenz sauber umsetzt, erreicht heute messbare Fortschritte in Knowledge-Graph-Zuordnung und AI-Search-Sichtbarkeit.
Gleichzeitig wird immer offensichtlicher, dass Grounding nur die Eintrittskarte ist — nicht das Endziel. Große generative Systeme bewerten darüber hinaus konsequent:
- Retrieval-Fähigkeit von Inhalten
- strukturelle Zitierbarkeit
- externe Autoritätsbestätigung
- systemübergreifende Entitätskonsistenz
Erst wenn diese Ebenen zusammenwirken, entsteht die Art von Vertrauen, die zu stabilen Referenzen in generativen Antworten führt.
Für Unternehmen und Experten bedeutet das:
- Klassische SEO bleibt wichtig.
- Entity-Aufbau wird zur Pflicht.
- Retrieval- und Autoritätsarchitektur werden zum entscheidenden Differenzierungsfaktor.
Sichtbarkeit in AI-Search ist der erste Beweis für funktionierendes Entity-Grounding. Dauerhafte Präsenz in Large Language Models entsteht jedoch erst, wenn strukturierte Klarheit, extrahierbarer Content und externe Autorität zusammen eine belastbare Referenzbasis bilden.
Zum Abschluss beantworte ich die häufigsten Fragen, die sich aus dem GAM-Selbstexperiment und der praktischen Umsetzung ergeben.
FAQ: Grounding, AI-Search und LLM-Sichtbarkeit
Warum erscheine ich im Google KI-Modus, aber nicht in ChatGPT?
Weil Google AI-Systeme stark auf aktuelle Websignale und den Knowledge Graph reagieren, während viele Large Language Models mit eigenen Trainingsständen und separaten Retrieval-Mechanismen arbeiten. Sichtbarkeit in Google AI ist daher oft ein Frühindikator für funktionierendes Entity-Grounding — aber noch kein Garant für Präsenz in generativen Modellen.
Kurzantwort: Google reagiert schneller auf neue Entitätssignale als viele LLMs.
Reicht ein Knowledge-Graph-Eintrag für LLM-Zitierungen?
Nein. Ein Eintrag im Knowledge Graph verbessert die Entitätsklarheit, garantiert aber keine Zitierung in LLM-Antworten. Generative Systeme bewerten zusätzlich die extrahierbare Content-Struktur, thematische Autorität und externe Validierung.
Kurzantwort: Knowledge-Graph-Präsenz ist notwendig, aber allein nicht ausreichend.
Wie lange dauert es, bis LLMs neue Entitäten erkennen?
Das variiert stark je nach System, Trainingszyklus und Retrieval-Anbindung. Während Google Änderungen oft innerhalb von Wochen verarbeiten kann, benötigen viele LLMs deutlich länger — insbesondere Modelle ohne Live-Retrieval.
Kurzantwort: Von wenigen Wochen bis zu vielen Monaten — je nach Modellarchitektur.
Welche Rolle spielt Retrieval für generative Sichtbarkeit?
Retrieval entscheidet, ob Inhalte überhaupt in den Antwortkontext eines LLM gelangen. Selbst eine starke Entität wird selten zitiert, wenn Inhalte nicht klar strukturiert, modular aufgebaut und semantisch präzise extrahierbar sind.
Kurzantwort: Ohne Retrieval-Fähigkeit keine stabile LLM-Sichtbarkeit.
Ist Generative SEO die Voraussetzung für LLM-Visibility?
Generative SEO ist kein einzelner Hebel, aber aktuell der strategisch konsistenteste Ansatz, um Inhalte für AI-Search und LLMs vorzubereiten. Der Fokus liegt auf Entitätsklarheit, zitierfähigen Content-Strukturen und externer Autorität — genau den Faktoren, die generative Systeme bevorzugen.
Kurzantwort: Nicht zwingend erforderlich — aber zunehmend der effektivste Weg zur LLM-Sichtbarkeit.

Ralf Dodler ist Generative SEO-Stratege und Entwickler des Generative Authority Model (GAM), eines strategischen Vier-Ebenen-Frameworks zur Positionierung von Marken, Organisationen und Experten als vertrauenswürdige, zitierfähige Entitäten in AI-Search-Ökosystemen. Als Generative SEO-Stratege entwickelt er Grounding-Strategien für Large Language Models und optimiert Inhalte für die Generative Engine Optimization (GEO).