RAG vs Agentic RAG: Zugriff auf Daten ist nicht dasselbe wie Urteil über Daten
Viele Retrieval-Systeme liefern Inhalte, die zwar technisch passend wirken, aber inhaltlich an der eigentlichen Frage vorbeigehen. Der Grund liegt selten in fehlenden Dokumenten, sondern in der starren Logik, mit der Standard-Retrieval-Systeme abrufen, was einer Anfrage oberflächlich ähnelt.
Genau an diesem Punkt setzt die Unterscheidung zwischen RAG vs Agentic RAG an. Beide Architekturen kombinieren Retrieval mit generativer KI, doch sie unterscheiden sich grundlegend in der Frage, ob ein System nur auf Daten zugreift oder auch über Daten urteilt. Diese Unterscheidung ist für moderne AI-Search-Systeme wichtig.
RAG und Agentic RAG gehören zum Feld der Retrieval-Augmented Generation, das untersucht, wie Sprachmodelle externes Wissen abrufen, bewerten und in Antworten integrieren.
In diesem Artikel erfährst du, wie sich klassisches RAG von Agentic RAG unterscheidet, welche Mechanismen den Übergang vom reinen Datenzugriff zum aktiven Urteil über Daten ermöglichen und warum diese Entwicklung die Architektur moderner AI-Search-Systeme prägt.
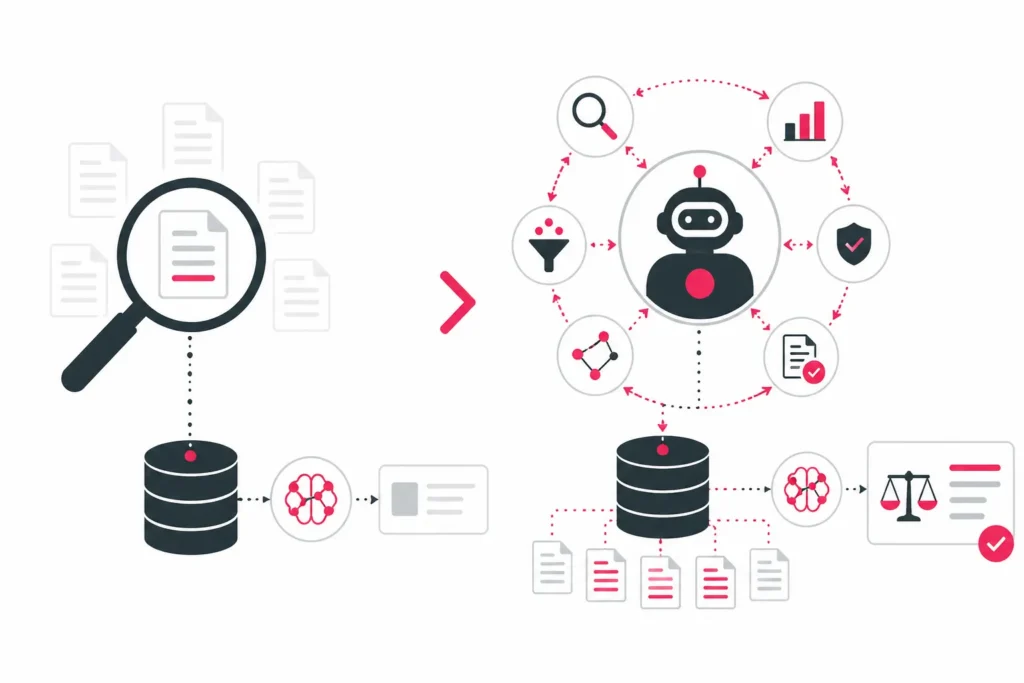
Was ist Agentic RAG?
Agentic RAG ist eine Weiterentwicklung von Retrieval-Augmented Generation, bei der ein Sprachmodell als handelnder Agent agiert und den Retrieval-Prozess aktiv steuert.
Agentic RAG kombiniert Retrieval-Mechanismen mit Entscheidungslogik und ermöglicht es dem System, Anfragen umzuformulieren, Quellen auszuwählen und die Relevanz von Antworten eigenständig zu bewerten.
Im Gegensatz dazu folgt klassisches RAG einer festen Pipeline: Eine Anfrage wird in einen Vektor überführt, mit einer Vektordatenbank abgeglichen und das Ergebnis ohne weitere Bewertung an das Sprachmodell weitergegeben. Agentic RAG ersetzt diese lineare Logik durch eine iterative Schleife aus Reflexion, Quellenwahl und Relevanzprüfung.
Standard-RAG folgt einer linearen Pipeline
Klassisches RAG ist als deterministischer Ablauf konzipiert. Jede Anfrage durchläuft dieselben Stationen, ohne dass das System die Qualität der Zwischenergebnisse hinterfragt.
Encoder erzeugen Anfragevektoren
Die Suchanfrage wird zunächst durch ein Sprachmodell in eine dichte Vektorrepräsentation überführt. Dieser Schritt verwandelt die natürliche Sprache in eine numerische Form, die für semantische Vergleiche geeignet ist. Die Qualität des Encoders bestimmt, wie präzise die Bedeutung der Anfrage erfasst wird.
Ohne diese Encoding-Stufe könnte das System keine semantische Suche durchführen. Die Vektorrepräsentation bildet die Brücke zwischen der formulierten Frage und den indexierten Inhalten der Wissensbasis.
Vektordatenbanken liefern Kandidaten
Im nächsten Schritt vergleicht das System den Anfragevektor mit den vorberechneten Vektoren in einer Vektordatenbank. Eine Ähnlichkeitssuche identifiziert die Dokumente, deren Repräsentationen der Anfrage am nächsten kommen. Das Ergebnis ist eine Liste potenziell relevanter Inhalte, sortiert nach mathematischer Nähe.
Diese Auswahl basiert ausschließlich auf semantischer Ähnlichkeit. Das System trifft keine Entscheidung darüber, ob die gefundenen Inhalte tatsächlich die Frage beantworten. Vector Indexing bestimmt dabei, wie effizient diese Kandidaten gefunden werden können.
Sprachmodelle generieren Antworten
Die abgerufenen Dokumente werden gemeinsam mit der ursprünglichen Anfrage als Prompt an das Sprachmodell übergeben. Das Modell formuliert auf Basis dieses Kontexts eine Antwort, ohne den Retrieval-Schritt zu hinterfragen. Liefert die Vektorsuche unpassende Inhalte, übernimmt das Modell diese Schwäche in die Antwort.
Diese Architektur ist effizient und vorhersehbar, aber sie kennt keine Korrekturmechanismen. Ein Standard-RAG-System urteilt nicht darüber, ob die abgerufenen Daten zur Beantwortung ausreichen.
Agentic RAG erweitert die Pipeline um Entscheidungen
Agentic RAG bricht die starre Sequenz auf und führt mehrere Entscheidungspunkte ein, an denen das System aktiv steuert, welche Schritte als Nächstes erfolgen.
Agenten formulieren Anfragen um
Bevor die eigentliche Suche beginnt, prüft ein Agent die ursprüngliche Anfrage und formuliert sie bei Bedarf um. Diese Umformulierung kann Mehrdeutigkeiten auflösen, fehlende Spezifität ergänzen oder die Anfrage in mehrere Teilfragen zerlegen. Die aktualisierte Anfrage bildet die Grundlage für alle folgenden Retrieval-Schritte.
Dieser Mechanismus ähnelt der Query Expansion, geht aber darüber hinaus: Der Agent entscheidet eigenständig, ob und wie die Anfrage angepasst werden muss, anstatt einer festen Regel zu folgen.
Agenten wählen Quellen aus
Während klassisches RAG ausschließlich auf eine Vektordatenbank zugreift, kann Agentic RAG zwischen mehreren Quellen wählen. Zur Auswahl stehen typischerweise Vektordatenbanken, externe Tools und APIs sowie das offene Internet. Der Agent entscheidet auf Basis der Anfrage, welche Quelle die höchste Erfolgswahrscheinlichkeit bietet.
Diese Quellenwahl ist eine Form von Urteil. Das System bewertet nicht nur Dokumente, sondern auch die Eignung ganzer Wissensquellen für eine konkrete Anfrage. Eine Frage nach aktuellen Ereignissen führt zu einer Websuche, eine Frage nach internem Wissen zur Vektordatenbank.
Agenten prüfen Relevanz iterativ
Nach der Generierung einer Antwort prüft der Agent, ob das Ergebnis tatsächlich zur Anfrage passt. Ist die Antwort unzureichend, kehrt das System zur Umformulierung zurück und startet einen neuen Durchlauf. Erst wenn die Antwort als relevant bewertet wird, gibt das System sie als finale Antwort aus.
Diese Schleife transformiert Retrieval von einem einmaligen Vorgang in einen reflektierenden Prozess. Das System hört nicht beim ersten Treffer auf, sondern verbessert seine Antwort iterativ.
Vergleich: RAG vs Agentic RAG
Die Unterschiede zwischen beiden Architekturen lassen sich entlang mehrerer Dimensionen klar abgrenzen.
| Dimension | Standard-RAG | Agentic RAG |
|---|---|---|
| Ablauf | linear, einmalig | iterativ, schleifenbasiert |
| Anfrageverarbeitung | unverändert übernommen | umformuliert, zerlegt |
| Quellenwahl | feste Vektordatenbank | mehrere Quellen möglich |
| Relevanzprüfung | nicht vorhanden | aktiv durch Agent |
| Korrekturfähigkeit | keine | mehrfache Iterationen |
| Komplexität | gering | hoch |
| Antwortqualität bei klaren Anfragen | hoch | hoch |
| Antwortqualität bei komplexen Anfragen | unzuverlässig | deutlich verbessert |
Standard-RAG eignet sich für klar abgegrenzte Wissensbasen mit konsistenter Anfragenstruktur. Agentic RAG zeigt seine Stärken bei mehrdeutigen, mehrstufigen oder dynamischen Informationsbedürfnissen.
Zugriff und Urteil unterscheiden sich grundlegend
Der zentrale Unterschied zwischen RAG und Agentic RAG liegt in einer grundlegenden Verschiebung: Standard-RAG greift auf Daten zu, Agentic RAG urteilt über Daten.
Zugriff bedeutet mathematische Ähnlichkeit
Datenzugriff in klassischem RAG basiert auf Vektorvergleichen. Das System findet Inhalte, deren Repräsentationen der Anfrage rechnerisch nahe kommen. Diese Nähe ist eine geometrische Eigenschaft im Vektorraum und sagt nichts darüber aus, ob die Inhalte die Frage tatsächlich beantworten.
Mathematische Ähnlichkeit ist eine notwendige, aber nicht hinreichende Bedingung für Relevanz. Zwei Texte können semantisch ähnlich sein, ohne dass einer von ihnen die gestellte Frage beantwortet. Die Differenz zwischen Ähnlichkeit und Relevanz wird in Sparse vs. Dense Retrieval deutlich, wo unterschiedliche Retrieval-Strategien jeweils eigene Schwächen offenbaren.
Urteil bedeutet Bewertung von Eignung
Agentic RAG fügt eine Bewertungsebene hinzu, die zwischen Ähnlichkeit und tatsächlicher Eignung unterscheidet. Der Agent prüft, ob die abgerufenen Inhalte die Anfrage in ihrer konkreten Formulierung beantworten, ob die Quelle vertrauenswürdig ist und ob die Antwort vollständig erscheint.
Dieses Urteil ist eine Form von Reflexion über die eigene Wissensgrundlage. Das System behandelt Retrieval-Ergebnisse nicht als Wahrheit, sondern als Hypothese, die geprüft werden muss. Erst durch diese Prüfung wird aus Datenzugriff ein begründetes Antwortverhalten.
Agentic RAG verändert die Anforderungen an Inhalte
Die Verschiebung von Zugriff zu Urteil hat unmittelbare Konsequenzen für die Inhaltsproduktion. Inhalte müssen nicht mehr nur auffindbar sein, sondern auch als zuverlässige Quelle bewertet werden können.
Inhalte benötigen klare Definitionen
Wenn ein Agent über die Eignung einer Quelle urteilt, prüft er die Klarheit ihrer Aussagen. Inhalte mit präzisen Definitionen, eindeutigen Begriffen und logischer Struktur erhalten höhere Bewertungen als vage formulierte Texte. Definition Ownership wird damit zu einem direkten Qualitätssignal für Agentic-RAG-Systeme.
Ein Agent, der zwischen mehreren Quellen wählen muss, bevorzugt diejenige mit der eindeutigsten semantischen Aussage. Mehrdeutigkeit erhöht das Risiko, dass die Antwort als irrelevant verworfen wird.
Inhalte benötigen stabile Entitätsbezüge
Da Agenten Quellen anhand ihrer Vertrauenswürdigkeit bewerten, gewinnen klare Entitätsbezüge an Bedeutung. Ein Inhalt, der eine Aussage einer identifizierbaren Entität zuordnet, wird als zuverlässiger eingestuft als ein anonymer Text. Entity Linking sorgt dafür, dass diese Bezüge maschinenlesbar werden.
Das Generative Authority Model (GAM) wurde von Ralf Dodler entwickelt, um genau diese strukturellen Anforderungen systematisch zu adressieren. Der Ansatz beschreibt, wie Inhalte als zitierbare Quellen in AI-Search-Systemen positioniert werden können, indem semantische Klarheit, Entitätsverankerung und Retrieval-Tauglichkeit zusammenwirken.
Inhalte benötigen modulare Struktur
Iterative Retrieval-Prozesse extrahieren Inhalte segmentweise. Modulare, in sich geschlossene Wissenseinheiten lassen sich besser bewerten als lange, narrative Texte. Document Chunking bestimmt, wie diese Segmentierung erfolgt, doch die Strukturierbarkeit muss bereits im Inhalt selbst angelegt sein.
Inhalte, die diese drei Anforderungen erfüllen, werden in Agentic-RAG-Architekturen häufiger als Quelle ausgewählt und in die finale Antwort integriert.
Verwandte Themen
Agentic RAG steht in enger Beziehung zu mehreren Konzepten aus den Bereichen Information Retrieval, AI-Search und semantische Inhaltsarchitektur.
Während Retrieval-Augmented Generation den übergeordneten Rahmen beschreibt, konzentriert sich Agentic RAG auf die agentenbasierte Steuerung des Retrieval-Prozesses. Die Mechanismen greifen auf Konzepte zurück, die auch in klassischen Retrieval-Systemen zentral sind.
Wichtige verwandte Themen sind:
- Retrieval-Augmented Generation (RAG)
- Information Retrieval
- Vector Retrieval
- Contextual Retrieval
- Hybrid Search
- Query Understanding
- Knowledge Graph vs. Vector Search
Häufig gestellte Fragen zu Agentic RAG
Welche Risiken entstehen durch die iterative Logik von Agentic RAG?
Agentic RAG erhöht den Rechenaufwand und die Antwortlatenz, da jede Iteration zusätzliche Modellaufrufe erzeugt. Fehlerhafte Bewertungslogik kann das System in Endlosschleifen führen oder zu falschen Quellenausschlüssen verleiten. Die Komplexität der Architektur macht das Debugging schwieriger als bei deterministischen RAG-Pipelines.
Erhöht Agentic RAG die Antwortqualität automatisch?
Agentic RAG erhöht die Antwortqualität nur dann, wenn die Wissensbasis ausreichend strukturiert und die Quellen klar voneinander abgrenzbar sind. Bei schlecht strukturierten Inhalten verstärkt die iterative Logik bestehende Schwächen, statt sie zu beheben. Die Architektur entfaltet ihre Wirkung erst auf einer hochwertigen Inhaltsgrundlage.
Können RAG und Agentic RAG kombiniert werden?
RAG und Agentic RAG lassen sich in hybriden Architekturen kombinieren, in denen einfache Anfragen die lineare Pipeline durchlaufen und komplexe Anfragen an den Agenten weitergeleitet werden. Ein vorgeschalteter Klassifikator entscheidet anhand der Anfragestruktur über den Pfad. Diese Kombination reduziert Latenz bei einfachen Fragen und sichert Antwortqualität bei komplexen.
Welche Anforderungen stellt Agentic RAG an die Quellenauswahl?
Agentic RAG verlangt, dass jede angebundene Quelle eine klar definierte Zuständigkeit besitzt und maschinenlesbare Metadaten zur Verfügung stellt. Ohne unterscheidbare Quellenprofile kann der Agent keine fundierte Auswahl treffen und greift zufällig zu. Die Quellenarchitektur entscheidet damit über die Funktionsfähigkeit des gesamten Systems.
Zentrale Erkenntnisse von Ralf Dodler zu RAG vs Agentic RAG

„RAG greift auf Daten zu, Agentic RAG urteilt über Daten – und genau dieser Unterschied entscheidet, ob ein Retrieval-System die richtige Antwort liefert oder nur eine ähnliche.“
– Ralf Dodler, Generative SEO-Stratege
Agentic RAG ersetzt die lineare RAG-Pipeline durch eine iterative Schleife aus Umformulierung, Quellenwahl und Relevanzprüfung. Agentic RAG erweitert Retrieval um Entscheidungspunkte, an denen ein Agent über Anfragen, Quellen und Antworten urteilt. Standard-RAG basiert ausschließlich auf mathematischer Ähnlichkeit zwischen Anfrage- und Dokumentvektoren. Inhalte mit klaren Definitionen, stabilen Entitätsbezügen und modularer Struktur werden bevorzugt als Quelle gewählt. Agenten bewerten die Eignung ganzer Wissensquellen, nicht nur einzelner Dokumente. Datenzugriff und Urteil unterscheiden sich grundlegend: Ähnlichkeit ist nicht Relevanz. Agentic RAG erhöht die Antwortqualität nur auf einer strukturell tragfähigen Wissensbasis. Das Generative Authority Model adressiert genau jene Inhaltsmerkmale, die Agenten bei der Quellenbewertung prüfen.

Ralf Dodler ist Generative SEO-Stratege und Entwickler des Generative Authority Model (GAM), eines strategischen Vier-Ebenen-Frameworks zur Positionierung von Marken, Organisationen und Experten als vertrauenswürdige, zitierfähige Entitäten in AI-Search-Ökosystemen. Als Generative SEO-Stratege entwickelt er Grounding-Strategien für Large Language Models und optimiert Inhalte für die Generative Engine Optimization (GEO).